概念和基本架构
Kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多生产者、多订阅者,基 于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日 志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的 访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展

有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅 模式。Kafka就是一种发布-订阅模式。
对于消息中间件,消息分推拉两种模式。Kafka只有消息的拉取,没有推送,可以通过轮询实现消 息的推送
- Kafka在一个或多个可以跨越多个数据中心的服务器上作为集群运行。
- Kafka集群中按照主题分类管理,一个主题可以有多个分区,一个分区可以有多个副本分区。
- 每个记录由一个键,一个值和一个时间戳组成。
Kafka具有四个核心API:
- Producer API:允许应用程序将记录流发布到一个或多个Kafka主题。
- Consumer API:允许应用程序订阅一个或多个主题并处理为其生成的记录流。
- Streams API:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或多 个输出主题的输出流,从而有效地将输入流转换为输出流。
- Connector API:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生产 者或使用者。例如,关系数据库的连接器可能会捕获对表的所有更改。
Kafka优势
- 高吞吐量:单机每秒处理几十上百万的消息量。即使存储了许多TB的消息,它也保持稳定的 性能。
- 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失。
- 持久化数据存储:将消息持久化到磁盘。通过将数据持久化到硬盘以及replication防止数据丢 失。
- 零拷贝
- 顺序读,顺序写
- 利用Linux的页缓存
- 分布式系统,易于向外扩展。所有的Producer、Broker和Consumer都会有多个,均为分布 式的。无需停机即可扩展机器。多个Producer、Consumer可能是不同的应用。
- 可靠性 - Kafka是分布式,分区,复制和容错的。
- 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败 时能自动平衡
- 支持online和offline的场景。
- 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言
Kafka应用场景
日志收集:一个公司可以用Kafka可以收集各种服务的Log,通过Kafka以统一接口服务的方式开放 给各种Consumer;
消息系统:解耦生产者和消费者、缓存消息等;
用户活动跟踪:Kafka经常被用来记录Web用户或者App用户的各种活动,如浏览网页、搜索、点 击等活动,这些活动信息被各个服务器发布到Kafka的Topic中,然后消费者通过订阅这些Topic来做实 时的监控分析,亦可保存到数据库;
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作 的集中反馈,比如报警和报告;
流式处理:比如Spark Streaming和Storm。
基本架构
消息和批次
Kafka的数据单元称为消息。可以把消息看成是数据库里的一个“数据行”或一条“记录”。消息由字节 数组组成。
消息有键,键也是一个字节数组。当消息以一种可控的方式写入不同的分区时,会用到键。
为了提高效率,消息被分批写入Kafka。批次就是一组消息,这些消息属于同一个主题和分区。
把消息分成批次可以减少网络开销。批次越大,单位时间内处理的消息就越多,单个消息的传输时 间就越长。批次数据会被压缩,这样可以提升数据的传输和存储能力,但是需要更多的计算处理。
模式
消息模式(schema)有许多可用的选项,以便于理解。如JSON和XML,但是它们缺乏强类型处理 能力。Kafka的许多开发者喜欢使用Apache Avro。Avro提供了一种紧凑的序列化格式,模式和消息体 分开。当模式发生变化时,不需要重新生成代码,它还支持强类型和模式进化,其版本既向前兼容,也 向后兼容。
数据格式的一致性对Kafka很重要,因为它消除了消息读写操作之间的耦合性。
主题和分区
Kafka的消息通过主题进行分类。主题可比是数据库的表或者文件系统里的文件夹。主题可以被分 为若干分区,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力。

生产者和消费者
生产者创建消息。消费者消费消息。
一个消息被发布到一个特定的主题上。
生产者在默认情况下把消息均衡地分布到主题的所有分区上:
- 直接指定消息的分区
- 根据消息的key散列取模得出分区
- 轮询指定分区。
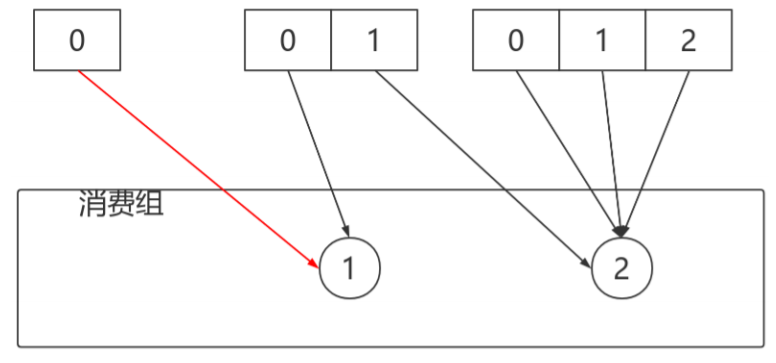
消费者通过偏移量来区分已经读过的消息,从而消费消息。
消费者是消费组的一部分。消费组保证每个分区只能被一个消费者使用,避免重复消费。
broker和集群
一个独立的Kafka服务器称为broker。broker接收来自生产者的消息,为消息设置偏移量,并提交 消息到磁盘保存。broker为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘上的消 息。单个broker可以轻松处理数千个分区以及每秒百万级的消息量。

每个集群都有一个broker是集群控制器(自动从集群的活跃成员中选举出来)。
控制器负责管理工作:
- 将分区分配给broker
- 监控broker
集群中一个分区属于一个broker,该broker称为分区首领。
一个分区可以分配给多个broker,此时会发生分区复制。
分区的复制提供了消息冗余,高可用。副本分区不负责处理消息的读写。
核心概念
Producer
生产者创建消息。
该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到 当前用于追加数据的 segment 文件中。
一般情况下,一个消息会被发布到一个特定的主题上。
- 默认情况下通过轮询把消息均衡地分布到主题的所有分区上。
- 在某些情况下,生产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现 的,分区器为键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的 消息会被写到同一个分区上。
- 生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
Consumer
消费者读取消息。
- 消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。
- 消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另一种元数据,它是一个不 断递增的整数值,在创建消息时,Kafka 会把它添加到消息里。在给定的分区里,每个消息的 偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在Zookeeper 或Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
- 消费者是消费组的一部分。群组保证每个分区只能被一个消费者使用。
- 如果一个消费者失效,消费组里的其他消费者可以接管失效消费者的工作,再平衡,分区重新 分配。

Broker
一个独立的Kafka 服务器被称为broker。
broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
- 如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个 partition。
- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的 一个partition,剩下的M个broker不存储该topic的partition数据。
- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一 个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka 集群数据不均衡。
broker 是集群的组成部分。每个集群都有一个broker 同时充当了集群控制器的角色(自动从集群 的活跃成员中选举出来)。
控制器负责管理工作,包括将分区分配给broker 和监控broker。
在集群中,一个分区从属于一个broker,该broker 被称为分区的首领。
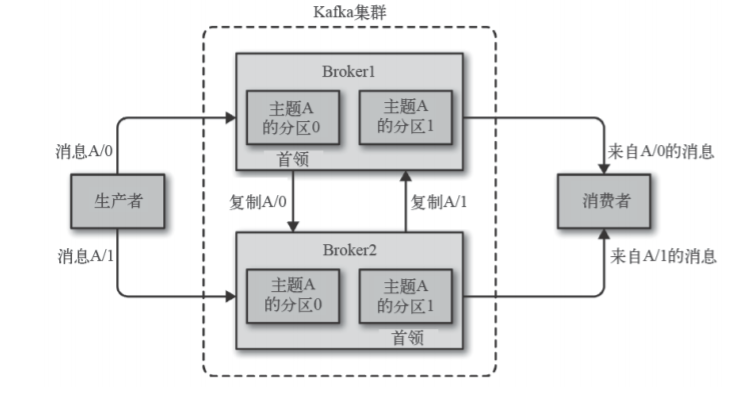
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
物理上不同Topic的消息分开存储。
主题就好比数据库的表,尤其是分库分表之后的逻辑表。
Partition
- 主题可以被分为若干个分区,一个分区就是一个提交日志。
- 消息以追加的方式写入分区,然后以先入先出的顺序读取。
- 无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
- Kafka 通过分区来实现数据冗余和伸缩性。
- 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。

Replicas
Kafka 使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存 在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。
副本有以下两种类型:
首领副本
每个分区都有一个首领副本。为了保证一致性,所有生产者请求和消费者请求都会经过这个副本。
跟随者副本
首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一的任务就是从首 领那里复制消息,保持与首领一致的状态。如果首领发生崩溃,其中的一个跟随者会被提升为新首领。
Offset
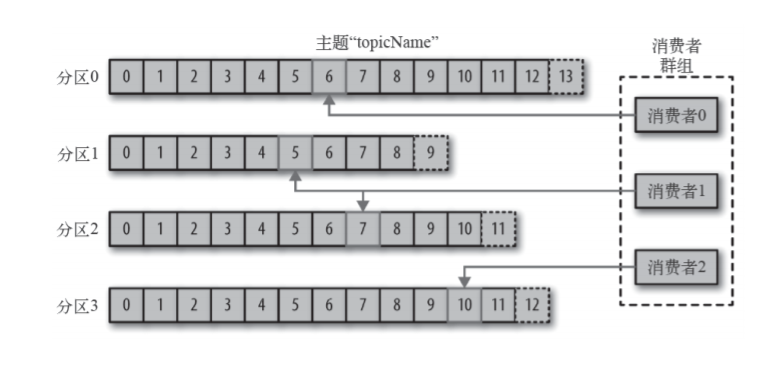
生产者Offset
消息写入的时候,每一个分区都有一个offset,这个offset就是生产者的offset,同时也是这个分区 的最新最大的offset。
有些时候没有指定某一个分区的offset,这个工作kafka帮我们完成。

消费者Offset

这是某一个分区的offset情况,生产者写入的offset是最新最大的值是12,而当Consumer A进行消 费时,从0开始消费,一直消费到了9,消费者的offset就记录在9,Consumer B就纪录在了11。等下一 次他们再来消费时,他们可以选择接着上一次的位置消费,当然也可以选择从头消费,或者跳到最近的 记录并从“现在”开始消费。
副本
Kafka通过副本保证高可用。副本分为首领副本(Leader)和跟随者副本(Follower)。
跟随者副本包括同步副本和不同步副本,在发生首领副本切换的时候,只有同步副本可以切换为首 领副本。
AR
分区中的所有副本统称为AR(Assigned Repllicas)。
AR=ISR+OSR
ISR
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集 合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消 息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程 度”是指可以忍受的滞后范围,这个范围可以通过参数进行配置。
OSR
与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas)。在正常 情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
HW
HW是High Watermak的缩写, 俗称高水位,它表示了一个特定消息的偏移量(offset),消费之 只能拉取到这个offset之前的消息。
LEO
LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset。

Kafka安装与配置
Java环境为前提
1、上传jdk-8u261-linux-x64.rpm到服务器并安装:
rpm -ivh jdk-8u261-linux-x64.rpm2、配置环境变量:
vim /etc/profile
# 生效
source /etc/profile
# 验证
java -version
Zookeeper的安装配置
1、上传zookeeper-3.4.14.tar.gz到服务器
2、解压到/opt:
tar -zxf zookeeper-3.4.14.tar.gz -C /opt
cd /opt/zookeeper-3.4.14/conf
# 复制zoo_sample.cfg命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
# 编辑zoo.cfg文件
vim zoo.cfg3、修改Zookeeper保存数据的目录,dataDir:
dataDir=/var/lagou/zookeeper/data4、编辑/etc/profile:
- 设置环境变量ZOO_LOG_DIR,指定Zookeeper保存日志的位置;
- ZOOKEEPER_PREFIX指向Zookeeper的解压目录;
- 将Zookeeper的bin目录添加到PATH中:

5、使配置生效:
source /etc/profile6、验证:

Kafka的安装与配置
1、上传kafka_2.12-1.0.2.tgz到服务器并解压:
tar -zxf kafka_2.12-1.0.2.tgz -C /opt2、配置环境变量并生效:
vim /etc/profile
3、配置/opt/kafka_2.12-1.0.2/config中的server.properties文件:
Kafka连接Zookeeper的地址,此处使用本地启动的Zookeeper实例,连接地址是 localhost:2181,后面的 myKafka 是Kafka在Zookeeper中的根节点路径:

4、启动Zookeeper:
zkServer.sh start5、确认Zookeeper的状态:

6、启动Kafka:
进入Kafka安装的根目录,执行如下命令:

启动成功,可以看到控制台输出的最后一行的started状态:

7、查看Zookeeper的节点:

8、此时Kafka是前台模式启动,要停止,使用Ctrl+C。
如果要后台启动,使用命令:
kafka-server-start.sh -daemon config/server.properties
查看Kafka的后台进程:
ps aux | grep kafka停止后台运行的Kafka:

生产与消费
1、kafka-topics.sh 用于管理主题。
# 列出现有的主题
[root@node1 ~]# kafka-topics.sh --list --zookeeper localhost:2181/myKafka
# 创建主题,该主题包含一个分区,该分区为Leader分区,它没有Follower分区副本。
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --create
--topic topic_1 --partitions 1 --replication-factor 1
# 查看分区信息
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --list
# 查看指定主题的详细信息
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --
describe --topic topic_1
# 删除指定主题
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --delete
--topic topic_12、kafka-console-producer.sh用于生产消息:
# 开启生产者
[root@node1 ~]# kafka-console-producer.sh --topic topic_1 --broker-list
localhost:90203、kafka-console-consumer.sh用于消费消息:
# 开启消费者
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 -
-topic topic_1
# 开启消费者方式二,从头消费,不按照偏移量消费
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 -
-topic topic_1 --from-beginningKafka开发实战
消息的发送与接收
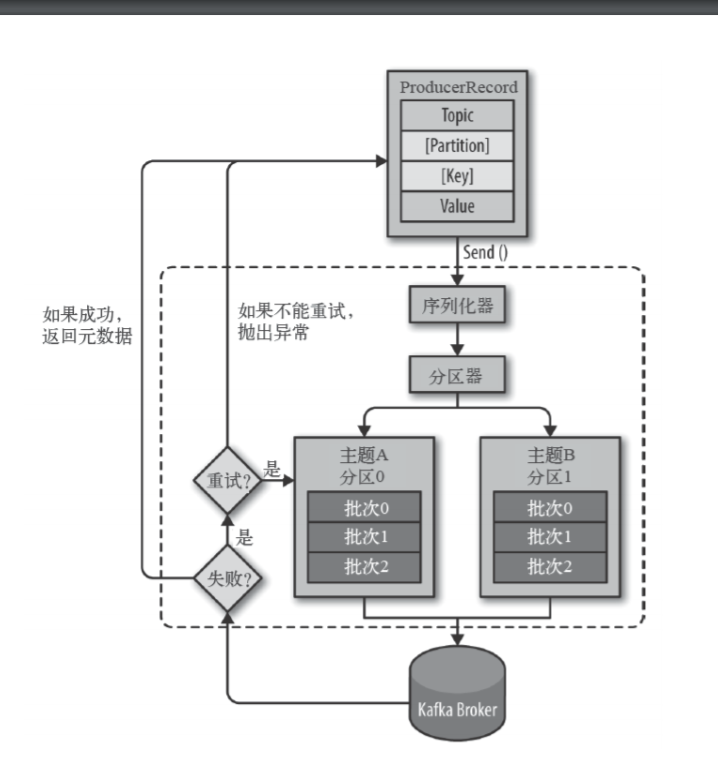
生产者主要的对象有: KafkaProducer , ProducerRecord 。
其中 KafkaProducer 是用于发送消息的类, ProducerRecord 类用于封装Kafka的消息。

其他参数可以从 org.apache.kafka.clients.producer.ProducerConfig 中找到。
消费者生产消息后,需要broker端的确认,可以同步确认,也可以异步确认。
同步确认效率低,异步确认效率高,但是需要设置回调对象。
生产者:
package com.lagou.kafka.demo.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
public class MyProducer1 {
public static void main(String[] args) throws InterruptedException,
ExecutionException, TimeoutException {
Map<String, Object> configs = new HashMap<>();
// 设置连接Kafka的初始连接用到的服务器地址
// 如果是集群,则可以通过此初始连接发现集群中的其他broker
configs.put("bootstrap.servers", "node1:9092");
// 设置key的序列化器
configs.put("key.serializer",
"org.apache.kafka.common.serialization.IntegerSerializer");
// 设置value的序列化器
configs.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
configs.put("acks", "1");
KafkaProducer<Integer, String> producer = new
KafkaProducer<Integer, String>(configs);
// 用于封装Producer的消息
ProducerRecord<Integer, String> record = new
ProducerRecord<Integer, String>(
"topic_1", // 主题名称
0, // 分区编号,现在只有一个分区,所以是0
0, // 数字作为key
"message 0" // 字符串作为value
);
// 发送消息,同步等待消息的确认
producer.send(record).get(3_000, TimeUnit.MILLISECONDS);
// 关闭生产者
producer.close();
}
}生产者2:
package com.lagou.kafka.demo.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.HashMap;
import java.util.Map;
public class MyProducer2 {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
configs.put("bootstrap.servers", "node1:9092");
configs.put("key.serializer",
"org.apache.kafka.common.serialization.IntegerSerializer");
configs.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<Integer, String> producer = new
KafkaProducer<Integer, String>(configs);
ProducerRecord<Integer, String> record = new
ProducerRecord<Integer, String>(
"topic_1",
0,
1,
"lagou message 2"
);
// 使用回调异步等待消息的确认
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception
exception) {
if (exception == null) {
System.out.println(
"主题:" + metadata.topic() + "\n"
+ "分区:" + metadata.partition() + "\n"
+ "偏移量:" + metadata.offset() + "\n"
+ "序列化的key字节:" +
metadata.serializedKeySize() + "\n"
+ "序列化的value字节:" +
metadata.serializedValueSize() + "\n"
+ "时间戳:" + metadata.timestamp()
);
} else {
System.out.println("有异常:" + exception.getMessage());
}
}
});
// 关闭连接
producer.close();
}
}生产者3:
package com.lagou.kafka.demo.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.HashMap;
import java.util.Map;
public class MyProducer3 {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
configs.put("bootstrap.servers", "node1:9092");
configs.put("key.serializer",
"org.apache.kafka.common.serialization.IntegerSerializer");
configs.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<Integer, String> producer = new
KafkaProducer<Integer, String>(configs);
for (int i = 100; i < 200; i++) {
ProducerRecord<Integer, String> record = new
ProducerRecord<Integer, String>(
"topic_1",
0,
i,
"lagou message " + i
);
// 使用回调异步等待消息的确认
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception
exception) {
if (exception == null) {
System.out.println(
"主题:" + metadata.topic() + "\n"
+ "分区:" + metadata.partition() +
"\n"
+ "偏移量:" + metadata.offset() + "\n"
+ "序列化的key字节:" +
metadata.serializedKeySize() + "\n"
+ "序列化的value字节:" +
metadata.serializedValueSize() + "\n"
+ "时间戳:" + metadata.timestamp()
);
} else {
System.out.println("有异常:" +
exception.getMessage());
}
}
});
}
// 关闭连接
producer.close();
}
} 消息消费流程:
消费者:
package com.lagou.kafka.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.lang.reflect.Array;
import java.util.*;
import java.util.regex.Pattern;
public class MyConsumer1 {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
// 指定bootstrap.servers属性作为初始化连接Kafka的服务器。
// 如果是集群,则会基于此初始化连接发现集群中的其他服务器。
configs.put("bootstrap.servers", "node1:9092");
// key的反序列化器
configs.put("key.deserializer",
"org.apache.kafka.common.serialization.IntegerDeserializer");
// value的反序列化器
configs.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
configs.put("group.id", "consumer.demo");
// 创建消费者对象
KafkaConsumer<Integer, String> consumer = new
KafkaConsumer<Integer, String>(configs);
// final Pattern pattern = Pattern.compile("topic_\\d");
final Pattern pattern = Pattern.compile("topic_[0-9]");
// 消费者订阅主题或分区
// consumer.subscribe(pattern);
// consumer.subscribe(pattern, new ConsumerRebalanceListener() {
final List<String> topics = Arrays.asList("topic_1");
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition>
partitions) {
partitions.forEach(tp -> {
System.out.println("剥夺的分区:" + tp.partition());
});
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition>
partitions) {
partitions.forEach(tp -> {
System.out.println(tp.partition());
});
}
});
// 拉取订阅主题的消息
final ConsumerRecords<Integer, String> records =
consumer.poll(3_000);
// 获取topic_1主题的消息
final Iterable<ConsumerRecord<Integer, String>> topic1Iterable =
records.records("topic_1");
// 遍历topic_1主题的消息
topic1Iterable.forEach(record -> {
System.out.println("========================================");
System.out.println("消息头字段:" +
Arrays.toString(record.headers().toArray()));
System.out.println("消息的key:" + record.key());
System.out.println("消息的偏移量:" + record.offset());
System.out.println("消息的分区号:" + record.partition());
System.out.println("消息的序列化key字节数:" +
record.serializedKeySize());
System.out.println("消息的序列化value字节数:" +
record.serializedValueSize());
System.out.println("消息的时间戳:" + record.timestamp());
System.out.println("消息的时间戳类型:" + record.timestampType());
System.out.println("消息的主题:" + record.topic());
System.out.println("消息的值:" + record.value());
});
// 关闭消费者
consumer.close();
}
}SpringBoot Kafka
1. pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.lagou.kafka.demo</groupId>
<artifactId>demo-02-springboot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo-02-springboot</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>2. application.properties
spring.application.name=springboot-kafka-02
server.port=8080
# 用于建立初始连接的broker地址
spring.kafka.bootstrap-servers=node1:9092
# producer用到的key和value的序列化类
spring.kafka.producer.keyserializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.valueserializer=org.apache.kafka.common.serialization.StringSerializer
# 默认的批处理记录数
spring.kafka.producer.batch-size=16384
# 32MB的总发送缓存
spring.kafka.producer.buffer-memory=33554432
# consumer用到的key和value的反序列化类
spring.kafka.consumer.keydeserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.valuedeserializer=org.apache.kafka.common.serialization.StringDeserializer
# consumer的消费组id
spring.kafka.consumer.group-id=spring-kafka-02-consumer
# 是否自动提交消费者偏移量
spring.kafka.consumer.enable-auto-commit=true
# 每隔100ms向broker提交一次偏移量
spring.kafka.consumer.auto-commit-interval=100
# 如果该消费者的偏移量不存在,则自动设置为最早的偏移量
spring.kafka.consumer.auto-offset-reset=earliest3. Demo02SpringbootApplication.java
package com.lagou.kafka.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Demo02SpringbootApplication {
public static void main(String[] args) {
SpringApplication.run(Demo02SpringbootApplication.class, args);
}
}4. KafkaConfig.java
package com.lagou.kafka.demo.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaConfig {
@Bean
public NewTopic topic1() {
return new NewTopic("ntp-01", 5, (short) 1);
}
@Bean
public NewTopic topic2() {
return new NewTopic("ntp-02", 3, (short) 1);
}
}5. KafkaSyncProducerController.java
package com.lagou.kafka.demo.controller;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ExecutionException;
@RestController
public class KafkaSyncProducerController {
@Autowired
private KafkaTemplate template;
@RequestMapping("send/sync/{message}")
public String sendSync(@PathVariable String message) {
ListenableFuture future = template.send(
new ProducerRecord<Integer, String>(
"topic-spring-02",
0,
1,
message));
try {
// 同步等待broker的响应
Object o = future.get();
SendResult<Integer, String> result = (SendResult<Integer,
String>) o;
System.out.println(result.getRecordMetadata().topic()
+ result.getRecordMetadata().partition()
+ result.getRecordMetadata().offset());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return "success";
}
}6. KafkaAsyncProducerController
package com.lagou.kafka.demo.controller;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class KafkaAsyncProducerController {
@Autowired
private KafkaTemplate<Integer, String> template;
@RequestMapping("send/async/{message}")
public String asyncSend(@PathVariable String message) {
ProducerRecord<Integer, String> record = new
ProducerRecord<Integer, String>(
"topic-spring-02",
0,
3,
message
);
ListenableFuture<SendResult<Integer, String>> future =
template.send(record);
// 添加回调,异步等待响应
future.addCallback(new ListenableFutureCallback<SendResult<Integer,
String>>() {
@Override
public void onFailure(Throwable throwable) {
System.out.println("发送失败: " + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<Integer, String> result) {
System.out.println("发送成功:" +
result.getRecordMetadata().topic() + "\t"
+ result.getRecordMetadata().partition() + "\t"
+ result.getRecordMetadata().offset());
}
});
return "success";
}
}7. MyConsumer.java
package com.lagou.kafka.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
public class MyConsumer {
@KafkaListener(topics = "topic-spring-02")
public void onMessage(ConsumerRecord<Integer, String> record) {
Optional<ConsumerRecord<Integer, String>> optional =
Optional.ofNullable(record);
if (optional.isPresent()) {
System.out.println(
record.topic() + "\t"
+ record.partition() + "\t"
+ record.offset() + "\t"
+ record.key() + "\t"
+ record.value());
}
}
}服务端参数配置
$KAFKA_HOME/config/server.properties文件中的配置。
zookeeper.connect
该参数用于配置Kafka要连接的Zookeeper/集群的地址。
它的值是一个字符串,使用逗号分隔Zookeeper的多个地址。Zookeeper的单个地址是 host:port 形式的,可以在最后添加Kafka在Zookeeper中的根节点路径。 如:
zookeeper.connect=node2:2181,node3:2181,node4:2181/myKafka
listeners
用于指定当前Broker向外发布服务的地址和端口。
与 advertised.listeners 配合,用于做内外网隔离。
内外网隔离配置:
listener.security.protocol.map
监听器名称和安全协议的映射配置。
比如,可以将内外网隔离,即使它们都使用SSL。
listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL每个监听器的名称只能在map中出现一次。
inter.broker.listener.name
用于配置broker之间通信使用的监听器名称,该名称必须在advertised.listeners列表中。
inter.broker.listener.name=EXTERNALlisteners
用于配置broker监听的URI以及监听器名称列表,使用逗号隔开多个URI及监听器名称。
如果监听器名称代表的不是安全协议,必须配置listener.security.protocol.map。
每个监听器必须使用不同的网络端口。
advertised.listeners
需要将该地址发布到zookeeper供客户端使用,如果客户端使用的地址与listeners配置不同。
可以在zookeeper的 get /myKafka/brokers/ids/ 中找到。
在IaaS环境,该条目的网络接口得与broker绑定的网络接口不同。
如果不设置此条目,就使用listeners的配置。跟listeners不同,该条目不能使用0.0.0.0网络端口。
advertised.listeners的地址必须是listeners中配置的或配置的一部分。
典型配置:

broker.id
该属性用于唯一标记一个Kafka的Broker,它的值是一个任意integer值。
当Kafka以分布式集群运行的时候,尤为重要。
最好该值跟该Broker所在的物理主机有关的,如主机名为 host1.lagou.com ,则 broker.id=1 , 如果主机名为 192.168.100.101 ,则 broker.id=101 等等。

log.dir
通过该属性的值,指定Kafka在磁盘上保存消息的日志片段的目录。
它是一组用逗号分隔的本地文件系统路径。
如果指定了多个路径,那么broker 会根据“最少使用”原则,把同一个分区的日志片段保存到同一个 路径下。
broker 会往拥有最少数目分区的路径新增分区,而不是往拥有最小磁盘空间的路径新增分区。