互斥锁
锁的可重入性
“可重入锁”是指当一个线程调用 object.lock()获取到锁,进入临界区后,再次调用object.lock(),仍 然可以获取到该锁。显然,通常的锁都要设计成可重入的,否则就会发生死锁。
synchronized关键字,就是可重入锁。如下所示:
在一个synchronized方法method1()里面调用另外一个synchronized方法method2()。如果 synchronized关键字不可重入,那么在method2()处就会发生阻塞,这显然不可行。
public void synchronized method1() {
// ...
method2();
// ...
}
public void synchronized method2() {
// ...
}类继承层次
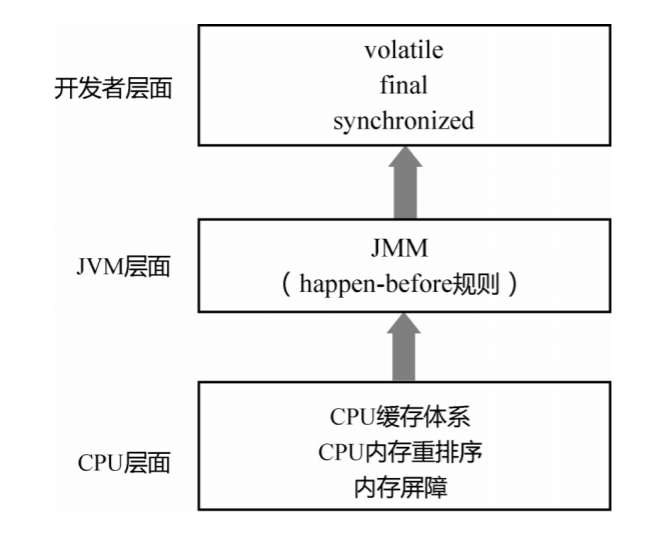
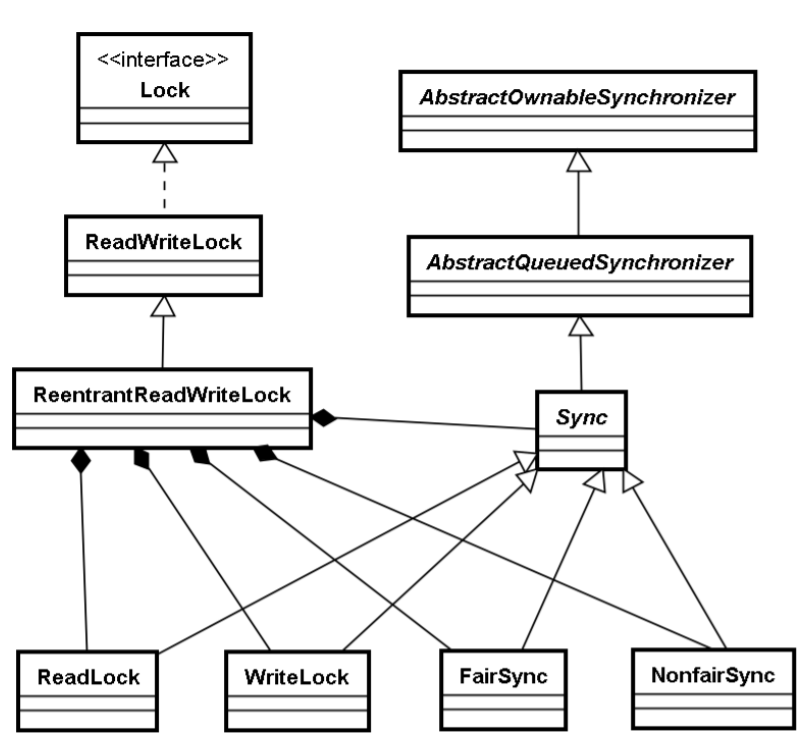
在正式介绍锁的实现原理之前,先看一下 Concurrent 包中的与互斥锁(ReentrantLock)相关类之 间的继承层次,如下图所示:
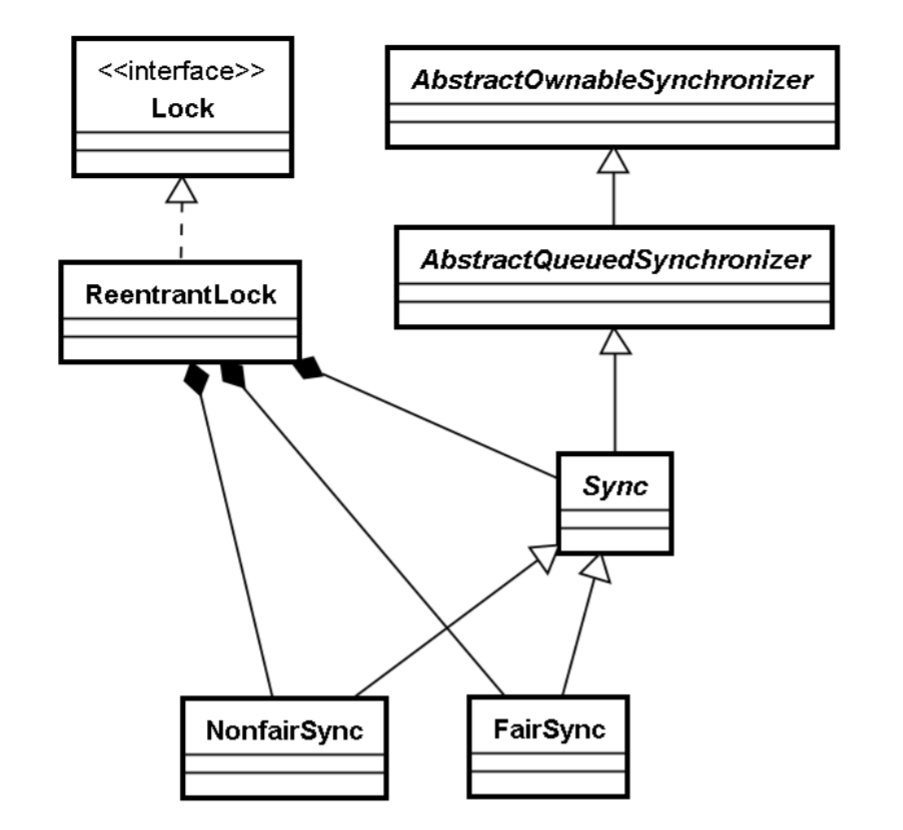
Lock是一个接口,其定义如下:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}常用的方法是lock()/unlock()。lock()不能被中断,对应的lockInterruptibly()可以被中断。
ReentrantLock本身没有代码逻辑,实现都在其内部类Sync中:
public class ReentrantLock implements Lock, java.io.Serializable {
private final Sync sync;
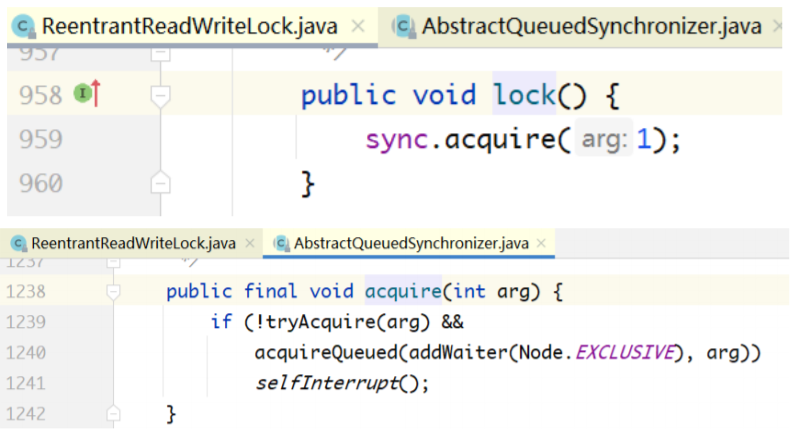
public void lock() {
sync.acquire(1);
}
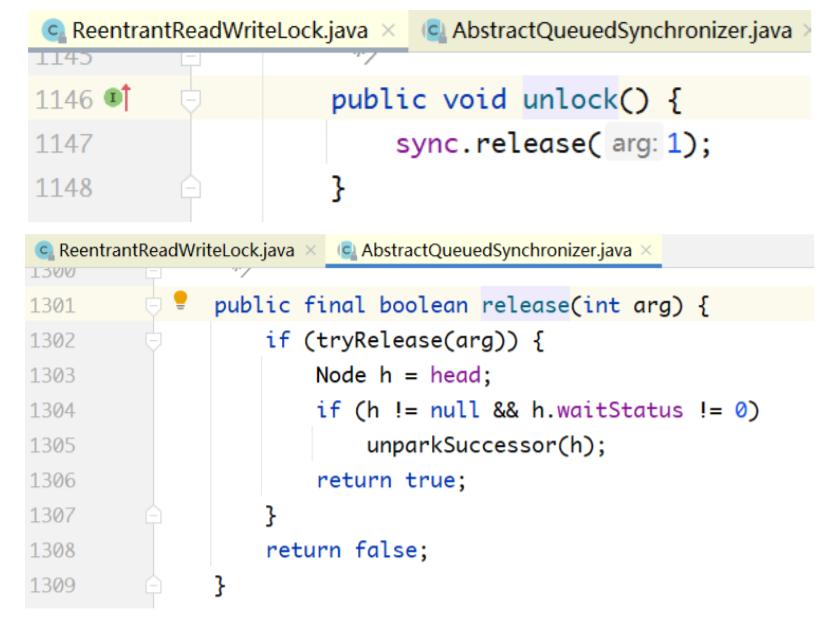
public void unlock() {
sync.release(1);
}
// ...
}锁的公平性vs.非公平性
Sync是一个抽象类,它有两个子类FairSync与NonfairSync,分别对应公平锁和非公平锁。从下面 的ReentrantLock构造方法可以看出,会传入一个布尔类型的变量fair指定锁是公平的还是非公平的,默 认为非公平的。
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}什么叫公平锁和非公平锁呢?先举个现实生活中的例子,一个人去火车站售票窗口买票,发现现场 有人排队,于是他排在队伍末尾,遵循先到者优先服务的规则,这叫公平;如果他去了不排队,直接冲 到窗口买票,这叫作不公平。
对应到锁的例子,一个新的线程来了之后,看到有很多线程在排队,自己排到队伍末尾,这叫公 平;线程来了之后直接去抢锁,这叫作不公平。默认设置的是非公平锁,其实是为了提高效率,减少线 程切换。
锁实现的基本原理
Sync的父类AbstractQueuedSynchronizer经常被称作队列同步器(AQS),这个类非常重要,该 类的父类是AbstractOwnableSynchronizer。
此处的锁具备synchronized功能,即可以阻塞一个线程。为了实现一把具有阻塞或唤醒功能的锁, 需要几个核心要素:
- 需要一个state变量,标记该锁的状态。state变量至少有两个值:0、1。对state变量的操作, 使用CAS保证线程安全。
- 需要记录当前是哪个线程持有锁。
- 需要底层支持对一个线程进行阻塞或唤醒操作。
- 需要有一个队列维护所有阻塞的线程。这个队列也必须是线程安全的无锁队列,也需要使用 CAS。
针对要素1和2,在上面两个类中有对应的体现:
public abstract class AbstractOwnableSynchronizer implements
java.io.Serializable {
// ...
private transient Thread exclusiveOwnerThread; // 记录持有锁的线程
}
public abstract class AbstractQueuedSynchronizer extends
AbstractOwnableSynchronizer implements java.io.Serializable {
private volatile int state; // 记录锁的状态,通过CAS修改state的值。
// ...
} state取值不仅可以是0、1,还可以大于1,就是为了支持锁的可重入性。例如,同样一个线程,调 用5次lock,state会变成5;然后调用5次unlock,state减为0。
当state=0时,没有线程持有锁,exclusiveOwnerThread=null;
当state=1时,有一个线程持有锁,exclusiveOwnerThread=该线程;
当state > 1时,说明该线程重入了该锁。
对于要素3,Unsafe类提供了阻塞或唤醒线程的一对操作原语,也就是park/unpark。
public native void unpark(Object thread);
public native void park(boolean isAbsolute, long time);有一个LockSupport的工具类,对这一对原语做了简单封装:
public class LockSupport {
// ...
private static final Unsafe U = Unsafe.getUnsafe();
public static void park() {
U.park(false, 0L);
}
public static void unpark(Thread thread) {
if (thread != null)
U.unpark(thread);
}
}在当前线程中调用park(),该线程就会被阻塞;在另外一个线程中,调用unpark(Thread thread),传入一个被阻塞的线程,就可以唤醒阻塞在park()地方的线程。
unpark(Thread thread),它实现了一个线程对另外一个线程的“精准唤醒”。notify也只是唤醒某一 个线程,但无法指定具体唤醒哪个线程。
针对要素4,在AQS中利用双向链表和CAS实现了一个阻塞队列。如下所示:
public abstract class AbstractQueuedSynchronizer {
// ...
static final class Node {
volatile Thread thread; // 每个Node对应一个被阻塞的线程
volatile Node prev;
volatile Node next;
// ...
}
private transient volatile Node head;
private transient volatile Node tail;
// ...
}阻塞队列是整个AQS核心中的核心。如下图所示,head指向双向链表头部,tail指向双向链表尾 部。入队就是把新的Node加到tail后面,然后对tail进行CAS操作;出队就是对head进行CAS操作,把 head向后移一个位置。
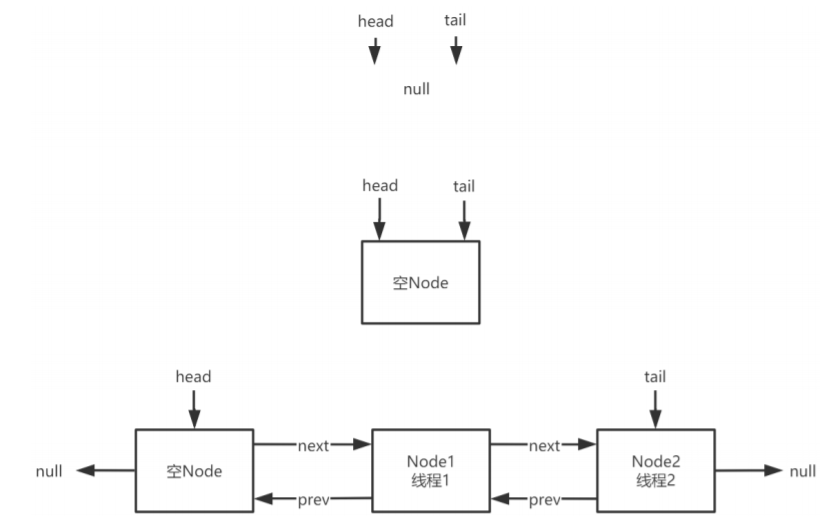
初始的时候,head=tail=NULL;然后,在往队列中加入阻塞的线程时,会新建一个空的Node,让 head和tail都指向这个空Node;之后,在后面加入被阻塞的线程对象。所以,当head=tail的时候,说 明队列为空。
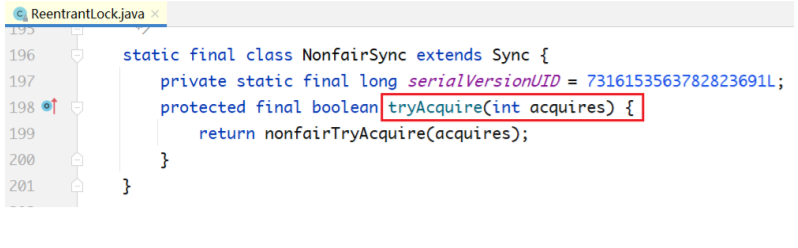
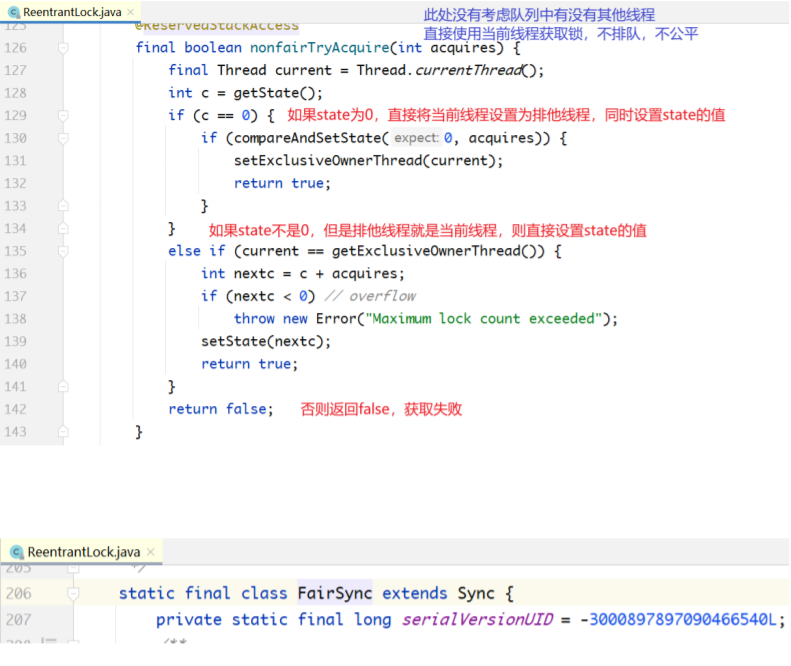
公平与非公平的lock()实现差异
下面分析基于AQS,ReentrantLock在公平性和非公平性上的实现差异。
阻塞队列与唤醒机制
下面进入锁的最为关键的部分,即acquireQueued(...)方法内部一探究竟。
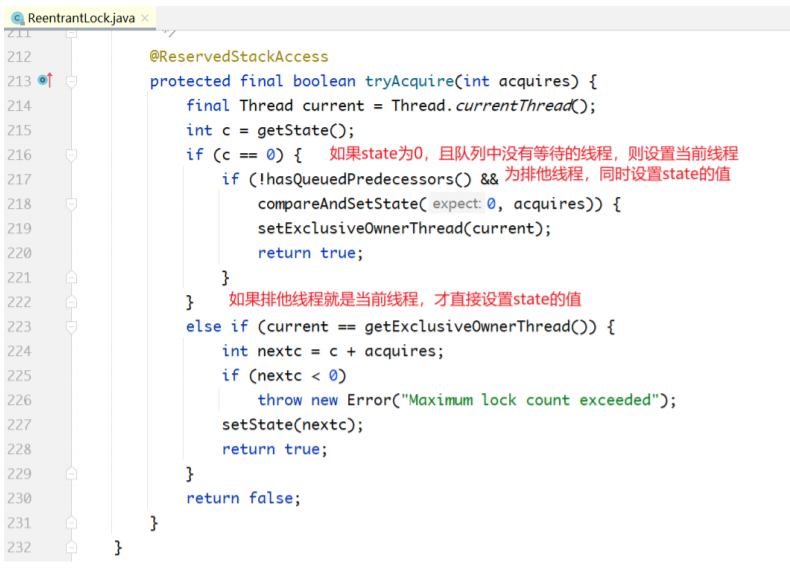
先说addWaiter(...)方法,就是为当前线程生成一个Node,然后把Node放入双向链表的尾部。要注 意的是,这只是把Thread对象放入了一个队列中而已,线程本身并未阻塞。
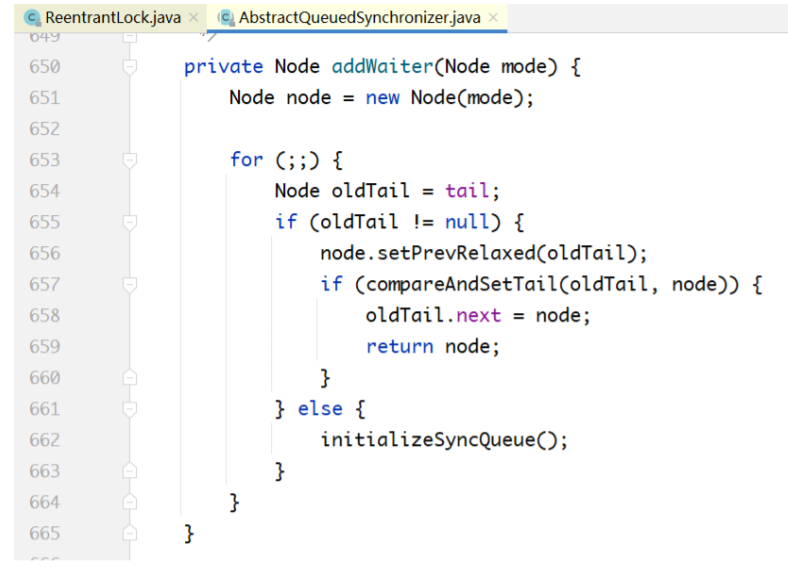
创建节点,尝试将节点追加到队列尾部。获取tail节点,将tail节点的next设置为当前节点。
如果tail不存在,就初始化队列。
在addWaiter(...)方法把Thread对象加入阻塞队列之后的工作就要靠acquireQueued(...)方法完成。 线程一旦进入acquireQueued(...)就会被无限期阻塞,即使有其他线程调用interrupt()方法也不能将其唤 醒,除非有其他线程释放了锁,并且该线程拿到了锁,才会从accquireQueued(...)返回。
进入acquireQueued(...),该线程被阻塞。在该方法返回的一刻,就是拿到锁的那一刻,也就是被唤 醒的那一刻,此时会删除队列的第一个元素(head指针前移1个节点)。
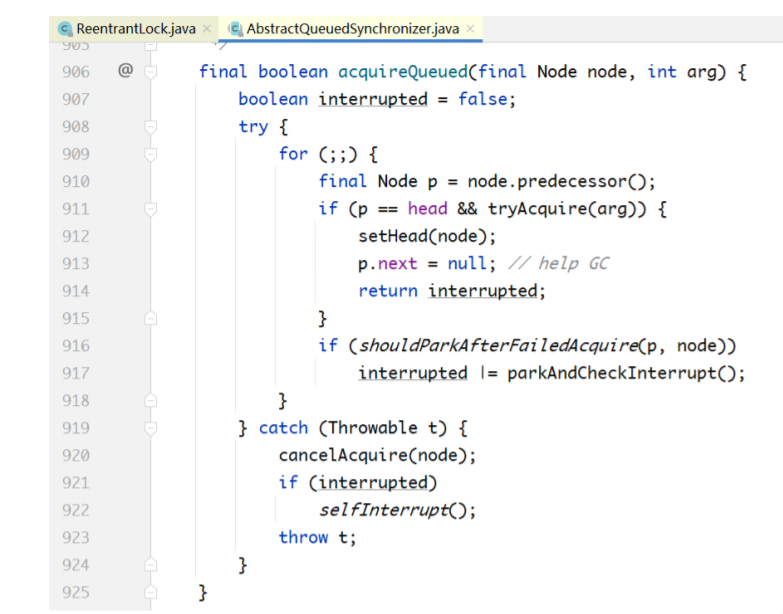
首先,acquireQueued(...)方法有一个返回值,表示什么意思呢?虽然该方法不会中断响应,但它会 记录被阻塞期间有没有其他线程向它发送过中断信号。如果有,则该方法会返回true;否则,返回 false。
基于这个返回值,才有了下面的代码:
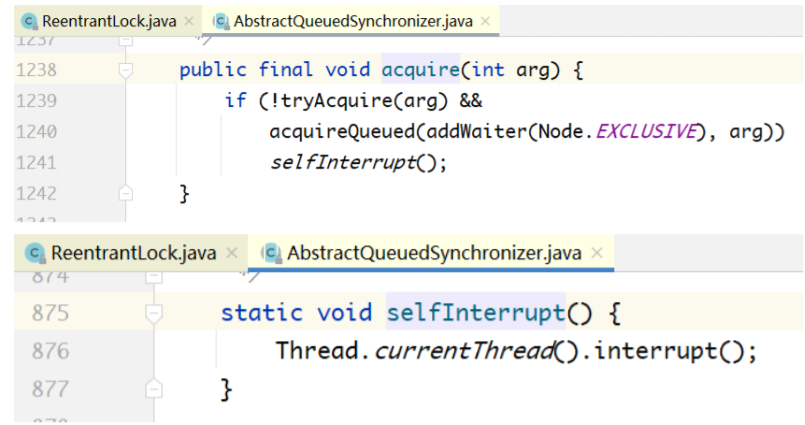
当 acquireQueued(...)返回 true 时,会调用 selfInterrupt(),自己给自己发送中断信号,也就是自 己把自己的中断标志位设为true。之所以要这么做,是因为自己在阻塞期间,收到其他线程中断信号没 有及时响应,现在要进行补偿。这样一来,如果该线程在lock代码块内部有调用sleep()之类的阻塞方 法,就可以抛出异常,响应该中断信号。
阻塞就发生在下面这个方法中:

线程调用 park()方法,自己把自己阻塞起来,直到被其他线程唤醒,该方法返回。
park()方法返回有两种情况。
- 其他线程调用了unpark(Thread t)。
- 其他线程调用了t.interrupt()。这里要注意的是,lock()不能响应中断,但LockSupport.park() 会响应中断。
也正因为LockSupport.park()可能被中断唤醒,acquireQueued(...)方法才写了一个for死循环。唤 醒之后,如果发现自己排在队列头部,就去拿锁;如果拿不到锁,则再次自己阻塞自己。不断重复此过 程,直到拿到锁。
被唤醒之后,通过Thread.interrupted()来判断是否被中断唤醒。如果是情况1,会返回false;如果 是情况2,则返回true。
unlock()实现分析
说完了lock,下面分析unlock的实现。unlock不区分公平还是非公平。
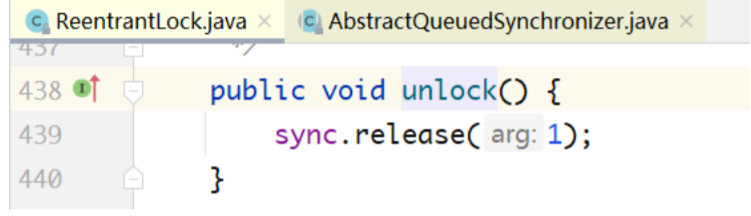

上图中,当前线程要释放锁,先调用tryRelease(arg)方法,如果返回true,则取出head,让head获 取锁。
对于tryRelease方法:

首先计算当前线程释放锁后的state值。
如果当前线程不是排他线程,则抛异常,因为只有获取锁的线程才可以进行释放锁的操作。
此时设置state,没有使用CAS,因为是单线程操作。
再看unparkSuccessor方法:
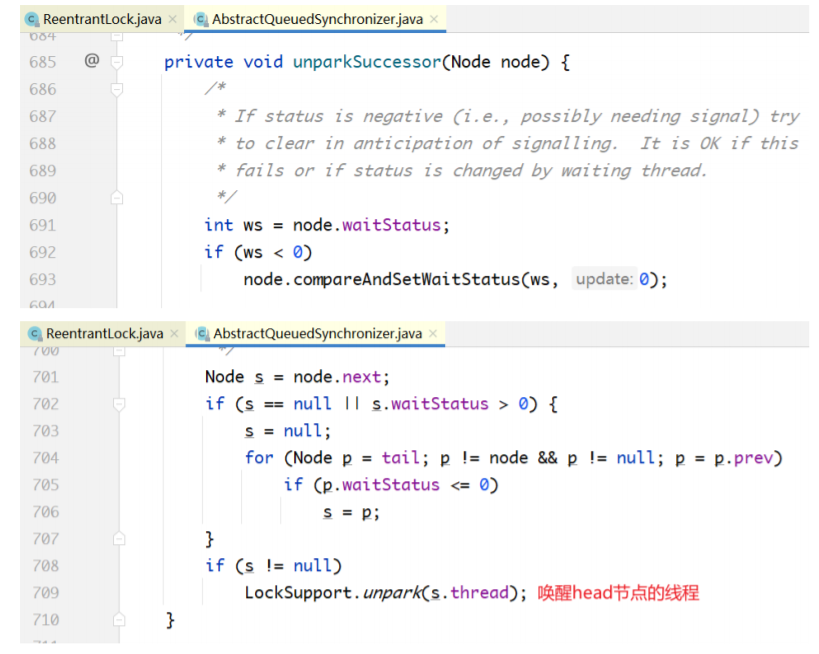
release()里面做了两件事:tryRelease(...)方法释放锁;unparkSuccessor(...)方法唤醒队列中的后继 者。
lockInterruptibly()实现分析
上面的 lock 不能被中断,这里的 lockInterruptibly()可以被中断:

这里的 acquireInterruptibly(...)也是 AQS 的模板方法,里面的 tryAcquire(...)分别被 FairSync和 NonfairSync实现。
主要看doAcquireInterruptibly(...)方法:
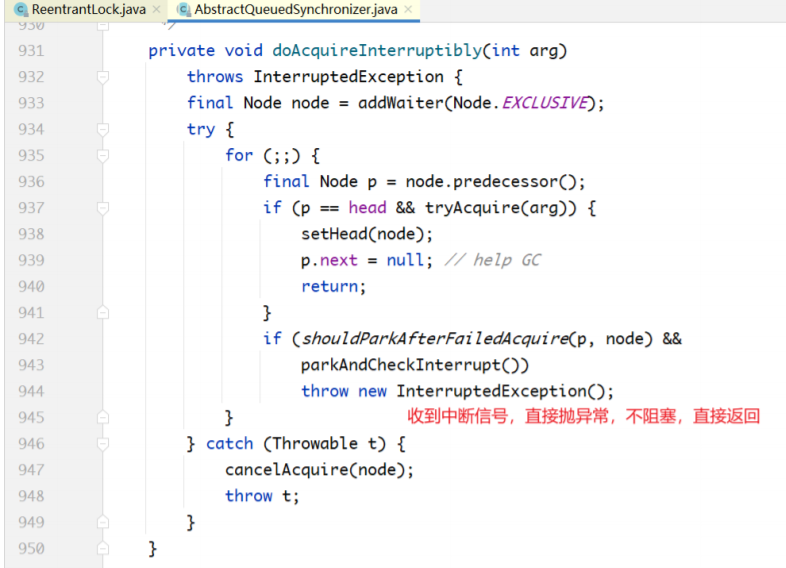
当parkAndCheckInterrupt()返回true的时候,说明有其他线程发送中断信号,直接抛出 InterruptedException,跳出for循环,整个方法返回。
tryLock()实现分析
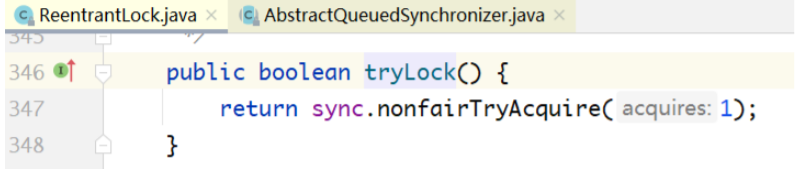
tryLock()实现基于调用非公平锁的tryAcquire(...),对state进行CAS操作,如果操作成功就拿到锁; 如果操作不成功则直接返回false,也不阻塞。
读写锁
和互斥锁相比,读写锁(ReentrantReadWriteLock)就是读线程和读线程之间不互斥。
读读不互斥,读写互斥,写写互斥
类继承层次
ReadWriteLock是一个接口,内部由两个Lock接口组成。
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}
ReentrantReadWriteLock实现了该接口,使用方式如下:
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
Lock readLock = readWriteLock.readLock();
readLock.lock();
// 进行读取操作
readLock.unlock();
Lock writeLock = readWriteLock.writeLock();
writeLock.lock();
// 进行写操作
writeLock.unlock();也就是说,当使用 ReadWriteLock 的时候,并不是直接使用,而是获得其内部的读锁和写锁,然后 分别调用lock/unlock。
读写锁实现的基本原理
从表面来看,ReadLock和WriteLock是两把锁,实际上它只是同一把锁的两个视图而已。什么叫两 个视图呢?可以理解为是一把锁,线程分成两类:读线程和写线程。读线程和写线程之间不互斥(可以 同时拿到这把锁),读线程之间不互斥,写线程之间互斥。
从下面的构造方法也可以看出,readerLock和writerLock实际共用同一个sync对象。sync对象同互 斥锁一样,分为非公平和公平两种策略,并继承自AQS。
public ReentrantReadWriteLock() {
this(false);
}
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}同互斥锁一样,读写锁也是用state变量来表示锁状态的。只是state变量在这里的含义和互斥锁完全 不同。在内部类Sync中,对state变量进行了重新定义,如下所示:
abstract static class Sync extends AbstractQueuedSynchronizer {
// ...
static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 持有读锁的线程的重入次数
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
// 持有写锁的线程的重入次数
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
// ...
} 也就是把 state 变量拆成两半,低16位,用来记录写锁。但同一时间既然只能有一个线程写,为什 么还需要16位呢?这是因为一个写线程可能多次重入。例如,低16位的值等于5,表示一个写线程重入 了5次。
高16位,用来“读”锁。例如,高16位的值等于5,既可以表示5个读线程都拿到了该锁;也可以表示 一个读线程重入了5次。
为什么要把一个int类型变量拆成两半,而不是用两个int型变量分别表示读锁和写锁的状态呢?
这是因为无法用一次CAS 同时操作两个int变量,所以用了一个int型的高16位和低16位分别表示读 锁和写锁的状态。
当state=0时,说明既没有线程持有读锁,也没有线程持有写锁;当state != 0时,要么有线程持有 读锁,要么有线程持有写锁,两者不能同时成立,因为读和写互斥。这时再进一步通过 sharedCount(state)和exclusiveCount(state)判断到底是读线程还是写线程持有了该锁。
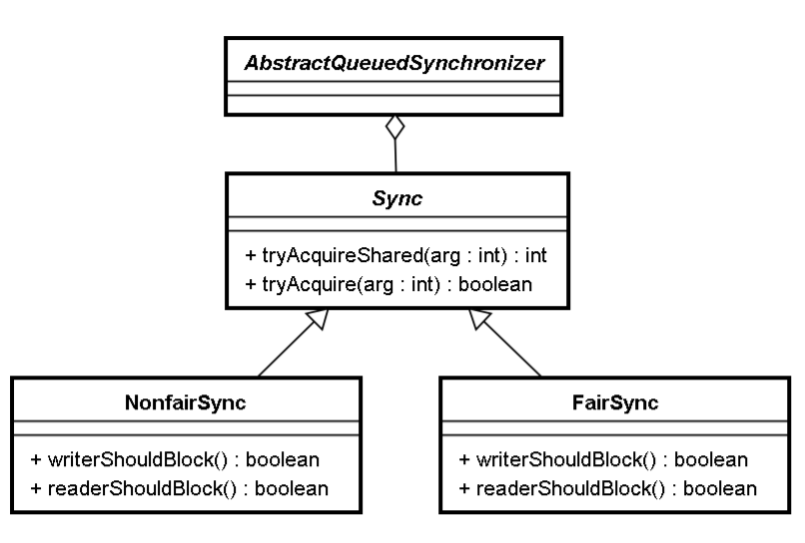
AQS的两对模板方法
下面介绍在ReentrantReadWriteLock的两个内部类ReadLock和WriteLock中,是如何使用state变 量的。
public static class ReadLock implements Lock, java.io.Serializable {
// ...
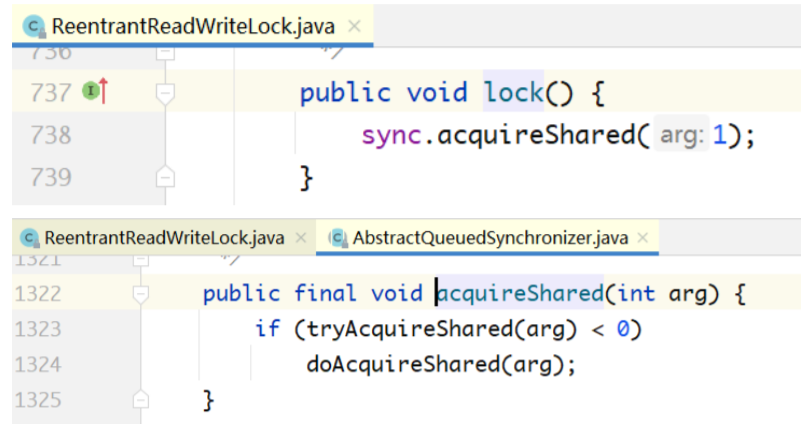
public void lock() {
sync.acquireShared(1);
}
public void unlock() {
sync.releaseShared(1);
}
// ...
}
public static class WriteLock implements Lock, java.io.Serializable {
// ...
public void lock() {
sync.acquire(1);
}
public void unlock() {
sync.release(1);
}
// ...
}acquire/release、acquireShared/releaseShared 是AQS里面的两对模板方法。互斥锁和读写锁的 写锁都是基于acquire/release模板方法来实现的。读写锁的读锁是基于acquireShared/releaseShared 这对模板方法来实现的。这两对模板方法的代码如下:
public abstract class AbstractQueuedSynchronizer extends
AbstractOwnableSynchronizer implements java.io.Serializable {
// ...
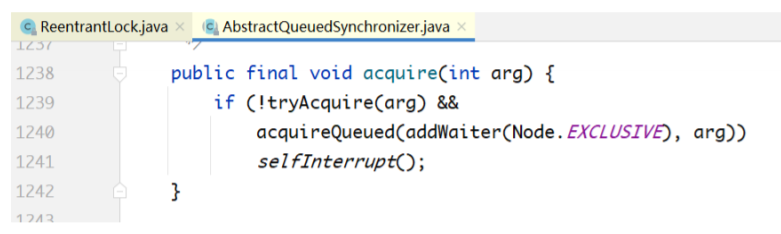
public final void acquire(int arg) {
if (!tryAcquire(arg) && // tryAcquire方法由多个Sync子
类实现
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0) // tryAcquireShared方法由多个Sync子类实
现
doAcquireShared(arg);
}
public final boolean release(int arg) {
if (tryRelease(arg)) { // tryRelease方法由多个Sync子类实现
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) { // tryReleaseShared方法由多个Sync子类实现
doReleaseShared();
return true;
}
return false;
}
// ...
}将读/写、公平/非公平进行排列组合,就有4种组合。如下图所示,上面的两个方法都是在Sync中实 现的。Sync中的两个方法又是模板方法,在NonfairSync和FairSync中分别有实现。最终的对应关系如 下:
- 读锁的公平实现:Sync.tryAccquireShared()+FairSync中的两个重写的子方法。
- 读锁的非公平实现:Sync.tryAccquireShared()+NonfairSync中的两个重写的子方法。
- 写锁的公平实现:Sync.tryAccquire()+FairSync中的两个重写的子方法。
- 写锁的非公平实现:Sync.tryAccquire()+NonfairSync中的两个重写的子方法。
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -8159625535654395037L;
// 写线程抢锁的时候是否应该阻塞
final boolean writerShouldBlock() {
// 写线程在抢锁之前永远不被阻塞,非公平锁
return false;
}
// 读线程抢锁的时候是否应该阻塞
final boolean readerShouldBlock() {
// 读线程抢锁的时候,当队列中第一个元素是写线程的时候要阻塞
return apparentlyFirstQueuedIsExclusive();
}
}
static final class FairSync extends Sync {
private static final long serialVersionUID = -2274990926593161451L;
// 写线程抢锁的时候是否应该阻塞
final boolean writerShouldBlock() {
// 写线程在抢锁之前,如果队列中有其他线程在排队,则阻塞。公平锁
return hasQueuedPredecessors();
}
// 读线程抢锁的时候是否应该阻塞
final boolean readerShouldBlock() {
// 读线程在抢锁之前,如果队列中有其他线程在排队,阻塞。公平锁
return hasQueuedPredecessors();
}
} 对于公平,比较容易理解,不论是读锁,还是写锁,只要队列中有其他线程在排队(排队等读锁, 或者排队等写锁),就不能直接去抢锁,要排在队列尾部。
对于非公平,读锁和写锁的实现策略略有差异。
写线程能抢锁,前提是state=0,只有在没有其他线程持有读锁或写锁的情况下,它才有机会去抢 锁。或者state != 0,但那个持有写锁的线程是它自己,再次重入。写线程是非公平的,即 writerShouldBlock()方法一直返回false。
对于读线程,假设当前线程被读线程持有,然后其他读线程还非公平地一直去抢,可能导致写线程 永远拿不到锁,所以对于读线程的非公平,要做一些“约束”。当发现队列的第1个元素是写线程的时候, 读线程也要阻塞,不能直接去抢。即偏向写线程。
WriteLock公平vs.非公平实现
写锁是排他锁,实现策略类似于互斥锁。
tryLock()实现分析
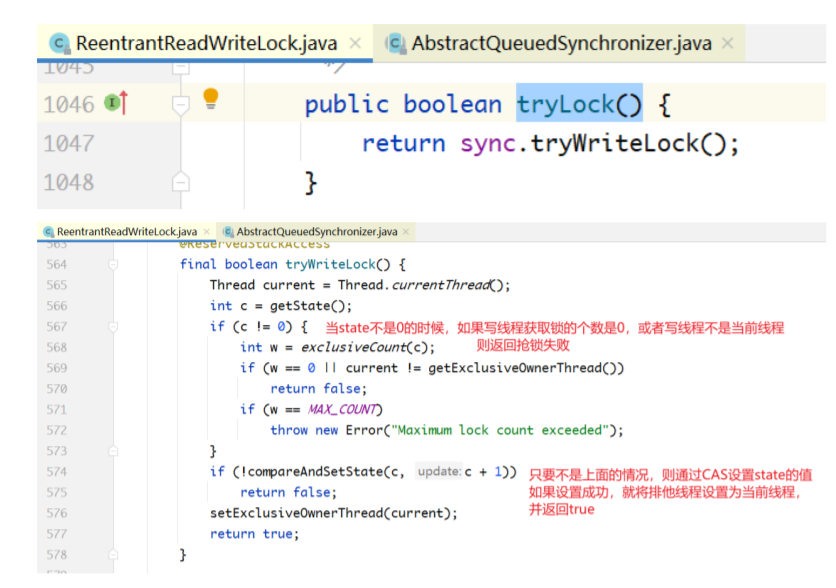
lock()方法:
在互斥锁部分讲过了。
tryLock和lock方法不区分公平/非公平。
unlock()实现分析
unlock()方法不区分公平/非公平。
ReadLock公平vs.非公平实现
读锁是共享锁,其实现策略和排他锁有很大的差异。
tryLock()实现分析
final boolean tryReadLock() {
// 获取当前线程
Thread current = Thread.currentThread();
for (;;) {
// 获取state值
int c = getState();
// 如果是写线程占用锁或者当前线程不是排他线程,则抢锁失败
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return false;
// 获取读锁state值
int r = sharedCount(c);
// 如果获取锁的值达到极限,则抛异常
if (r == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 使用CAS设置读线程锁state值
if (compareAndSetState(c, c + SHARED_UNIT)) {
// 如果r=0,则当前线程就是第一个读线程
if (r == 0) {
firstReader = current;
// 读线程个数为1
firstReaderHoldCount = 1;
// 如果写线程是当前线程
} else if (firstReader == current) {
// 如果第一个读线程就是当前线程,表示读线程重入读锁
firstReaderHoldCount++;
} else {
// 如果firstReader不是当前线程,则从ThreadLocal中获取当前线程的读锁
个数,并设置当前线程持有的读锁个数
HoldCounter rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return true;
}
}
}
unlock()实现分析

tryReleaseShared()的实现:
@ReservedStackAccess
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
// ...
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}因为读锁是共享锁,多个线程会同时持有读锁,所以对读锁的释放不能直接减1,而是需要通过一个 for循环+CAS操作不断重试。这是tryReleaseShared和tryRelease的根本差异所在。
Condition
Condition与Lock的关系
Condition本身也是一个接口,其功能和wait/notify类似,如下所示:
public interface Condition {
void await() throws InterruptedException;
boolean await(long time, TimeUnit unit) throws InterruptedException;
long awaitNanos(long nanosTimeout) throws InterruptedException;
void awaitUninterruptibly();
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
}wait()/notify()必须和synchronized一起使用,Condition也必须和Lock一起使用。因此,在Lock的 接口中,有一个与Condition相关的接口:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
// 所有的Condition都是从Lock中构造出来的
Condition newCondition();
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
}Condition的使用场景
以ArrayBlockingQueue为例。如下所示为一个用数组实现的阻塞队列,执行put(...)操作的时候,队 列满了,生产者线程被阻塞;执行take()操作的时候,队列为空,消费者线程被阻塞。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
//...
final Object[] items;
int takeIndex;
int putIndex;
int count;
// 一把锁+两个条件
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
// 构造器中创建一把锁加两个条件
lock = new ReentrantLock(fair);
// 构造器中创建一把锁加两个条件
notEmpty = lock.newCondition();
// 构造器中创建一把锁加两个条件
notFull = lock.newCondition();
}
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
// 非满条件阻塞,队列容量已满
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E e) {
// assert lock.isHeldByCurrentThread();
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = e;
if (++putIndex == items.length) putIndex = 0;
count++;
// put数据结束,通知消费者非空条件
notEmpty.signal();
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
// 阻塞于非空条件,队列元素个数为0,无法消费
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.isHeldByCurrentThread();
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E e = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length) takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
// 消费成功,通知非满条件,队列中有空间,可以生产元素了。
notFull.signal();
return e;
}
// ...
}Condition实现原理
可以发现,Condition的使用很方便,避免了wait/notify的生产者通知生产者、消费者通知消费者的 问题。具体实现如下:
由于Condition必须和Lock一起使用,所以Condition的实现也是Lock的一部分。首先查看互斥锁和 读写锁中Condition的构造方法:
public class ReentrantLock implements Lock, java.io.Serializable {
// ...
public Condition newCondition() {
return sync.newCondition();
}
}
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
// ...
private final ReentrantReadWriteLock.ReadLock readerLock;
private final ReentrantReadWriteLock.WriteLock writerLock;
// ...
public static class ReadLock implements Lock, java.io.Serializable {
// 读锁不支持Condition
public Condition newCondition() {
// 抛异常
throw new UnsupportedOperationException();
}
}
public static class WriteLock implements Lock, java.io.Serializable {
// ...
public Condition newCondition() {
return sync.newCondition();
}
// ...
}
// ...
}首先,读写锁中的 ReadLock 是不支持 Condition 的,读写锁的写锁和互斥锁都支持Condition。虽 然它们各自调用的是自己的内部类Sync,但内部类Sync都继承自AQS。因此,上面的代码 sync.newCondition最终都调用了AQS中的newCondition:
public abstract class AbstractQueuedSynchronizer extends
AbstractOwnableSynchronizer
implements java.io.Serializable {
public class ConditionObject implements Condition, java.io.Serializable
{
// Condition的所有实现,都在ConditionObject类中
}
}
abstract static class Sync extends AbstractQueuedSynchronizer {
final ConditionObject newCondition() {
return new ConditionObject();
}
}每一个Condition对象上面,都阻塞了多个线程。因此,在ConditionObject内部也有一个双向链表 组成的队列,如下所示:
public class ConditionObject implements Condition, java.io.Serializable {
private transient Node firstWaiter;
private transient Node lastWaiter;
}
static final class Node {
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node nextWaiter;
}下面来看一下在await()/notify()方法中,是如何使用这个队列的。
await()实现分析
public final void await() throws InterruptedException {
// 刚要执行await()操作,收到中断信号,抛异常
if (Thread.interrupted())
throw new InterruptedException();
// 加入Condition的等待队列
Node node = addConditionWaiter();
// 阻塞在Condition之前必须先释放锁,否则会死锁
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
// 阻塞当前线程
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
// 重新获取锁
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
// 被中断唤醒,抛中断异常
reportInterruptAfterWait(interruptMode);
}关于await,有几个关键点要说明:
1、 线程调用 await()的时候,肯定已经先拿到了锁。所以,在 addConditionWaiter()内部,对这 个双向链表的操作不需要执行CAS操作,线程天生是安全的,代码如下:
private Node addConditionWaiter() {
// ...
Node t = lastWaiter;
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}2、 在线程执行wait操作之前,必须先释放锁。也就是fullyRelease(node),否则会发生死锁。这 个和wait/notify与synchronized的配合机制一样。
3、 线程从wait中被唤醒后,必须用acquireQueued(node, savedState)方法重新拿锁。
4、 checkInterruptWhileWaiting(node)代码在park(this)代码之后,是为了检测在park期间是否 收到过中断信号。当线程从park中醒来时,有两种可能:一种是其他线程调用了unpark,另 一种是收到中断信号。这里的await()方法是可以响应中断的,所以当发现自己是被中断唤醒 的,而不是被unpark唤醒的时,会直接退出while循环,await()方法也会返回。
5、 isOnSyncQueue(node)用于判断该Node是否在AQS的同步队列里面。初始的时候,Node只 在Condition的队列里,而不在AQS的队列里。但执行notity操作的时候,会放进AQS的同步队 列。
awaitUninterruptibly()实现分析
与await()不同,awaitUninterruptibly()不会响应中断,其方法的定义中不会有中断异常抛出,下面 分析其实现和await()的区别。

可以看出,整体代码和 await()类似,区别在于收到异常后,不会抛出异常,而是继续执行while循 环。
notify()实现分析
public final void signal() {
// 只有持有锁的线程,才有资格调用signal()方法
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
// 发起通知
doSignal(first);
}
// 唤醒队列中的第1个线程
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) && (first = firstWaiter) != null);
}
final boolean transferForSignal(Node node) {
if (!node.compareAndSetWaitStatus(Node.CONDITION, 0))
return false;
// 先把Node放入互斥锁的同步队列中,再调用unpark方法
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !p.compareAndSetWaitStatus(ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}同 await()一样,在调用 notify()的时候,必须先拿到锁(否则就会抛出上面的异常),是因为前面 执行await()的时候,把锁释放了。
然后,从队列中取出firstWaiter,唤醒它。在通过调用unpark唤醒它之前,先用enq(node)方法把 这个Node放入AQS的锁对应的阻塞队列中。也正因为如此,才有了await()方法里面的判断条件:
while( ! isOnSyncQueue(node))
这个判断条件满足,说明await线程不是被中断,而是被unpark唤醒的。
notifyAll()与此类似。
StampedLock
为什么引入StampedLock
StampedLock是在JDK8中新增的,有了读写锁,为什么还要引入StampedLock呢?

可以看到,从ReentrantLock到StampedLock,并发度依次提高。
另一方面,因为ReentrantReadWriteLock采用的是“悲观读”的策略,当第一个读线程拿到锁之后, 第二个、第三个读线程还可以拿到锁,使得写线程一直拿不到锁,可能导致写线程“饿死”。虽然在其公 平或非公平的实现中,都尽量避免这种情形,但还有可能发生。
StampedLock引入了“乐观读”策略,读的时候不加读锁,读出来发现数据被修改了,再升级为“悲观 读”,相当于降低了“读”的地位,把抢锁的天平往“写”的一方倾斜了一下,避免写线程被饿死。
使用场景
在剖析其原理之前,下面先以官方的一个例子来看一下StampedLock如何使用。
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
// 多个线程调用该方法,修改x和y的值
void move(double deltaX, double deltaY) {
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
// 多个线程调用该方法,求距离
double distenceFromOrigin() {
// 使用“乐观读”
long stamp = sl.tryOptimisticRead();
// 将共享变量拷贝到线程栈
double currentX = x, currentY = y;
// 读期间有其他线程修改数据
if (!sl.validate(stamp)) {
// 读到的是脏数据,丢弃。
// 重新使用“悲观读”
stamp = sl.readLock();
try {
currentX = x;
currentY = y;
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
}如上面代码所示,有一个Point类,多个线程调用move()方法,修改坐标;还有多个线程调用 distanceFromOrigin()方法,求距离。
首先,执行move操作的时候,要加写锁。这个用法和ReadWriteLock的用法没有区别,写操作和写 操作也是互斥的。
关键在于读的时候,用了一个“乐观读”sl.tryOptimisticRead(),相当于在读之前给数据的状态做了 一个“快照”。然后,把数据拷贝到内存里面,在用之前,再比对一次版本号。如果版本号变了,则说明 在读的期间有其他线程修改了数据。读出来的数据废弃,重新获取读锁。关键代码就是下面这三行:
// 读取之前,获取数据的版本号
long stamp = sl.tryOptimisticRead();
// 读:将一份数据拷贝到线程的栈内存中
double currentX = x, currentY = y;
// 读取之后,对比读之前的版本号和当前的版本号,判断数据是否可用。
// 根据stamp判断在读取数据和使用数据期间,有没有其他线程修改数据
if (!sl.validate(stamp)) {
// ...
}要说明的是,这三行关键代码对顺序非常敏感,不能有重排序。因为 state 变量已经是volatile, 所以可以禁止重排序,但stamp并不是volatile的。为此,在validate(stamp)方法里面插入内存屏 障。
public boolean validate(long stamp) {
VarHandle.acquireFence();
return (stamp & SBITS) == (state & SBITS);
}“乐观读”的实现原理
首先,StampedLock是一个读写锁,因此也会像读写锁那样,把一个state变量分成两半,分别表示 读锁和写锁的状态。同时,它还需要一个数据的version。但是,一次CAS没有办法操作两个变量,所以 这个state变量本身同时也表示了数据的version。下面先分析state变量。
public class StampedLock implements java.io.Serializable {
private static final int LG_READERS = 7;
private static final long RUNIT = 1L;
private static final long WBIT = 1L << LG_READERS; // 第8位表示写锁
private static final long RBITS = WBIT - 1L; // 最低的7位表示读锁
private static final long RFULL = RBITS - 1L; // 读锁的数目
private static final long ABITS = RBITS | WBIT; // 读锁和写锁状态合二为一
private static final long SBITS = ~RBITS;
//
private static final long ORIGIN = WBIT << 1; // state的初始值
private transient volatile long state;
// ...
}如下图:用最低的8位表示读和写的状态,其中第8位表示写锁的状态,最低的7位表示读锁的状 态。因为写锁只有一个bit位,所以写锁是不可重入的。
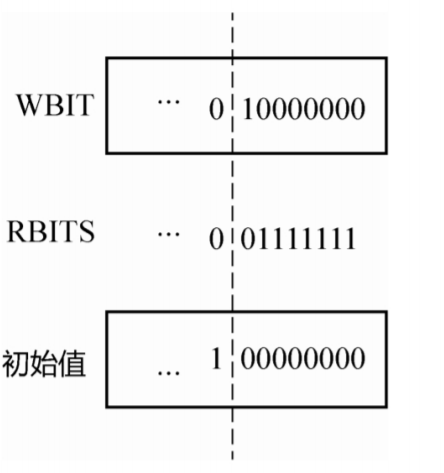
初始值不为0,而是把WBIT 向左移动了一位,也就是上面的ORIGIN 常量,构造方法如下所示。

为什么state的初始值不设为0呢?看乐观锁的实现:
public long tryOptimisticRead() {
long s;
return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L;
}
public boolean validate(long stamp) {
VarHandle.acquireFence();
return (stamp & SBITS) == (state & SBITS); // 当stamp=0时,validate永远返回
false
} 上面两个方法必须结合起来看:当state&WBIT != 0的时候,说明有线程持有写锁,上面的 tryOptimisticRead会永远返回0。这样,再调用validate(stamp),也就是validate(0)也会永远返 回false。这正是我们想要的逻辑:当有线程持有写锁的时候,validate永远返回false,无论写线程是否 释放了写锁。因为无论是否释放了(state回到初始值)写锁,state值都不为0,所以validate(0)永远 为false。
为什么上面的validate(...)方法不直接比较stamp=state,而要比较state&SBITS=state&SBITS 呢?
因为读锁和读锁是不互斥的!
所以,即使在“乐观读”的时候,state 值被修改了,但如果它改的是第7位,validate(...)还是会返回 true。
另外要说明的一点是,上面使用了内存屏障VarHandle.acquireFence();,是因为在这行代码的下一 行里面的stamp、SBITS变量不是volatile的,由此可以禁止其和前面的currentX=X,currentY=Y进行重 排序。
通过上面的分析,可以发现state的设计非常巧妙。只通过一个变量,既实现了读锁、写锁的状态记 录,还实现了数据的版本号的记录。
悲观读/写:“阻塞”与“自旋”策略实现差异
同ReadWriteLock一样,StampedLock也要进行悲观的读锁和写锁操作。不过,它不是基于AQS实 现的,而是内部重新实现了一个阻塞队列。如下所示
public class StampedLock implements java.io.Serializable {
// ...
static final class WNode {
volatile WNode prev;
volatile WNode next;
volatile WNode cowait;
volatile Thread thread;
volatile int status; // 取值:0,WAITING或CANCELLED
final int mode; // 取值:RMODE或WMODE
WNode(int m, WNode p) {
mode = m;
prev = p;
}
}
// ...
private transient volatile WNode whead;
private transient volatile WNode wtail;
// ...
} 这个阻塞队列和 AQS 里面的很像。
刚开始的时候,whead=wtail=NULL,然后初始化,建一个空节点,whead和wtail都指向这个空节 点,之后往里面加入一个个读线程或写线程节点。
但基于这个阻塞队列实现的锁的调度策略和AQS很不一样,也就是“自旋”。
在AQS里面,当一个线程CAS state失败之后,会立即加入阻塞队列,并且进入阻塞状态。
但在StampedLock中,CAS state失败之后,会不断自旋,自旋足够多的次数之后,如果还拿不到 锁,才进入阻塞状态。
为此,根据CPU的核数,定义了自旋次数的常量值。如果是单核的CPU,肯定不能自旋,在多核情 况下,才采用自旋策略。
private static final int NCPU = Runtime.getRuntime().availableProcessors();
// 自旋的次数,超过这个数字,进入阻塞。
private static final int SPINS = (NCPU > 1) ? 1 << 6 : 0;下面以写锁的加锁,也就是StampedLock的writeLock()方法为例,来看一下自旋的实现。
public long writeLock() {
long next;
return ((next = tryWriteLock()) != 0L) ? next : acquireWrite(false, 0L);
}
public long tryWriteLock() {
long s;
return (((s = state) & ABITS) == 0L) ? tryWriteLock(s) : 0L;
}如上面代码所示,当state&ABITS==0的时候,说明既没有线程持有读锁,也没有线程持有写锁,此 时当前线程才有资格通过CAS操作state。若操作不成功,则调用acquireWrite()方法进入阻塞队列,并 进行自旋,这个方法是整个加锁操作的核心,代码如下:
private long acquireWrite(boolean interruptible, long deadline) {
WNode node = null, p;
for (int spins = -1;;) { // 入列时自旋
long m, s, ns;
if ((m = (s = state) & ABITS) == 0L) {
if ((ns = tryWriteLock(s)) != 0L)
return ns; // 自旋的时候获取到锁,返回
}
else if (spins < 0)
// 计算自旋值
spins = (m == WBIT && wtail == whead) ? SPINS : 0;
else if (spins > 0) {
--spins; // 每次自旋获取锁,spins值减一
Thread.onSpinWait();
}
else if ((p = wtail) == null) { // 如果尾部节点是null,初始化队列
WNode hd = new WNode(WMODE, null);
// 头部和尾部指向一个节点
if (WHEAD.weakCompareAndSet(this, null, hd))
wtail = hd;
}
else if (node == null)
node = new WNode(WMODE, p);
else if (node.prev != p)
// p节点作为前置节点
node.prev = p;
// for循环唯一的break,成功将节点node添加到队列尾部,才会退出for循环
else if (WTAIL.weakCompareAndSet(this, p, node)) {
// 设置p的后置节点为node
p.next = node;
break;
}
}
boolean wasInterrupted = false;
for (int spins = -1;;) {
WNode h, np, pp; int ps;
if ((h = whead) == p) {
if (spins < 0)
spins = HEAD_SPINS;
else if (spins < MAX_HEAD_SPINS)
spins <<= 1;
for (int k = spins; k > 0; --k) { // spin at head
long s, ns;
if (((s = state) & ABITS) == 0L) {
if ((ns = tryWriteLock(s)) != 0L) {
whead = node;
node.prev = null;
if (wasInterrupted)
Thread.currentThread().interrupt();
return ns;
}
}
else
Thread.onSpinWait();
}
}
else if (h != null) { // 唤醒读取的线程
WNode c; Thread w;
while ((c = h.cowait) != null) {
if (WCOWAIT.weakCompareAndSet(h, c, c.cowait) &&
(w = c.thread) != null)
LockSupport.unpark(w);
}
}
if (whead == h) {
if ((np = node.prev) != p) {
if (np != null)
(p = np).next = node; // stale
}
else if ((ps = p.status) == 0)
WSTATUS.compareAndSet(p, 0, WAITING);
else if (ps == CANCELLED) {
if ((pp = p.prev) != null) {
node.prev = pp;
pp.next = node;
}
}
else {
long time; // 0 argument to park means no timeout
if (deadline == 0L)
time = 0L;
else if ((time = deadline - System.nanoTime()) <= 0L)
return cancelWaiter(node, node, false);
Thread wt = Thread.currentThread();
node.thread = wt;
if (p.status < 0 && (p != h || (state & ABITS) != 0L) &&
whead == h && node.prev == p) {
if (time == 0L)
// 阻塞,直到被唤醒
LockSupport.park(this);
else
// 计时阻塞
LockSupport.parkNanos(this, time);
}
node.thread = null;
if (Thread.interrupted()) {
if (interruptible)
// 如果被中断了,则取消等待
return cancelWaiter(node, node, true);
wasInterrupted = true;
}
}
}
}
}整个acquireWrite(...)方法是两个大的for循环,内部实现了非常复杂的自旋策略。在第一个大的for 循环里面,目的就是把该Node加入队列的尾部,一边加入,一边通过CAS操作尝试获得锁。如果获得 了,整个方法就会返回;如果不能获得锁,会一直自旋,直到加入队列尾部。
在第二个大的for循环里,也就是该Node已经在队列尾部了。这个时候,如果发现自己刚好也在队 列头部,说明队列中除了空的Head节点,就是当前线程了。此时,再进行新一轮的自旋,直到达到 MAX_HEAD_SPINS次数,然后进入阻塞。这里有一个关键点要说明:当release(...)方法被调用之后,会 唤醒队列头部的第1个元素,此时会执行第二个大的for循环里面的逻辑,也就是接着for循环里面park() 方法后面的代码往下执行。
另外一个不同于AQS的阻塞队列的地方是,在每个WNode里面有一个cowait指针,用于串联起所有 的读线程。例如,队列尾部阻塞的是一个读线程 1,现在又来了读线程 2、3,那么会通过cowait指针, 把1、2、3串联起来。1被唤醒之后,2、3也随之一起被唤醒,因为读和读之间不互斥。
明白加锁的自旋策略后,下面来看锁的释放操作。和读写锁的实现类似,也是做了两件事情:一是 把state变量置回原位,二是唤醒阻塞队列中的第一个节点。

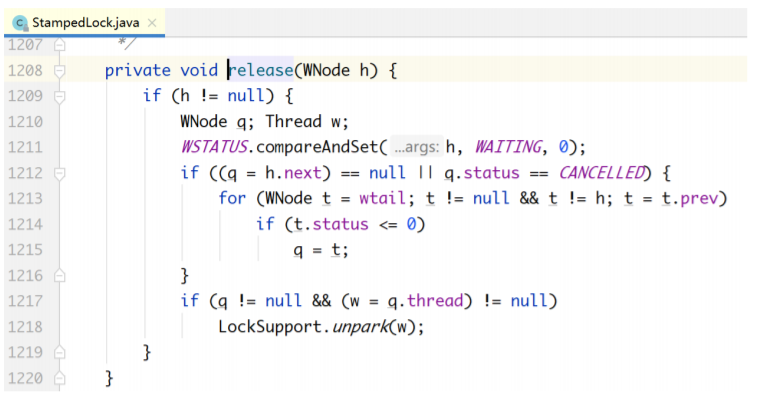
明白加锁的自旋策略后,下面来看锁的释放操作。和读写锁的实现类似,也是做了两件事情:一是 把state变量置回原位,二是唤醒阻塞队列中的第一个节点。