Filter DSL
Elasticsearch中的所有的查询都会触发相关度得分的计算。对于那些我们不需要相关度得分的场景下, Elasticsearch以过滤器的形式提供了另一种查询功能,过滤器在概念上类似于查询,但是它们有非常快 的执行速度,执行速度快主要有以下两个原因:
- 过滤器不会计算相关度的得分,所以它们在计算上更快一些。
- 过滤器可以被缓存到内存中,这使得在重复的搜索查询上,其要比相应的查询快出许多。
为了理解过滤器,可以将一个查询(像是match_all,match,bool等)和一个过滤器结合起来。我们 以范围过滤器为例,它允许我们通过一个区间的值来过滤文档。这通常被用在数字和日期的过滤上。 下面这个例子使用一个被过滤的查询,其返回price值是在200到1000之间(闭区间)的书。
示例
POST /book/_search
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"range": {
"price": {
"gte": 200,
"lte": 1000
}
}
}
}
}
}
#5.0 之后的写法
POST /book/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"range": {
"price": {
"gte": 200,
"lte": 1000
}
}
}
}
}
}分解上面的例子,被过滤的查询包含一个match_all查询(查询部分)和一个过滤器(filter部分)。我 们可以在查询部分中放入其他查询,在filter部分放入其它过滤器。在上面的应用场景中,由于所有的在 这个范围之内的文档都是平等的(或者说相关度都是一样的),没有一个文档比另一个文档更相关,所 以这个时候使用范围过滤器就非常合适了。通常情况下,要决定是使用过滤器还是使用查询,你就需要 问自己是否需要相关度得分。如果相关度是不重要的,使用过滤器,否则使用查询。查询和过滤器在概 念上类似于SELECT WHERE语句
定位非法搜索及原因
在开发的时候,我们可能会写到上百行的查询语句,如果出错的话,找起来很麻烦,Elasticsearch提供 了帮助开发人员定位不合法的查询的api _validate
示例
GET /book/_search?explain
{
"query": {
"match1": {
"name": "test"
}
}
}
使用 validate
GET /book/_validate/query?explain
{
"query": {
"match1": {
"name": "test"
}
}
}返回结果
{
"valid":false,
"error":"org.elasticsearch.common.ParsingException: no [query] registered for
[match1]"
}在查询时,不小心把 match 写成了 match1 ,通过 validate api 可以清楚的看到错误原因 正确查询返回
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"valid" : true,
"explanations" : [
{
"index" : "book",
"valid" : true,
"explanation" : "name:test"
}
]
}聚合分析
聚合介绍
聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出某字段 (或计算表达式的结果)的最大值、最小值,计算和、平均值等。Elasticsearch作为搜索引擎兼数据 库,同样提供了强大的聚合分析能力。
对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合 metric
而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行指标聚 合。在 ES 中group by 称为分桶,桶聚合 bucketing
Elasticsearch聚合分析语法
在查询请求体中以aggregations节点按如下语法定义聚合分析:
"aggregations" : {
"<aggregation_name>" : { <!--聚合的名字 -->
"<aggregation_type>" : { <!--聚合的类型 -->
<aggregation_body> <!--聚合体:对哪些字段进行聚合 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!--元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!--在聚合里面在定义子聚合 -
->
}
[,"<aggregation_name_2>" : { ... } ]*<!--聚合的名字 -->
}说明:aggregations 也可简写为 aggs
指标聚合
max min sum avg
示例一:查询所有书中最贵的
POST /book/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}文档计数count
示例: 统计price大于100的文档数量
POST /book/_count
{
"query": {
"range": {
"price" : {
"gt":100
}
}
}
}value_count 统计某字段有值的文档数
POST /book/_search?size=0
{
"aggs": {
"price_count": {
"value_count": {
"field": "price"
}
}
}
}cardinality值去重计数 基数
POST /book/_search?size=0
{
"aggs": {
"_id_count": {
"cardinality": {
"field": "_id"
}
},
"price_count": {
"cardinality": {
"field": "price"
}
}
}
}stats 统计 count max min avg sum 5个值
POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}Extended stats
高级统计,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间
POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"extended_stats": {
"field": "price"
}
}
}
}Percentiles 占比百分位对应的值统计
POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price"
}
}
}
}指定分位值
POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price",
"percents" : [75, 99, 99.9]
}
}
}
}Percentiles rank 统计值小于等于指定值的文档占比
统计price小于100和200的文档的占比
POST /book/_search?size=0
{
"aggs": {
"gge_perc_rank": {
"percentile_ranks": {
"field": "price",
"values": [
100,200
]
}
}
}
}桶聚合
Bucket Aggregations,桶聚合。
它执行的是对文档分组的操作(与sql中的group by类似),把满足相关特性的文档分到一个桶里,即 桶分,输出结果往往是一个个包含多个文档的桶(一个桶就是一个group)
bucket:一个数据分组
metric:对一个数据分组执行的统计
POST /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 200
},
{
"from": 200,
"to": 400
},
{
"from": 400,
"to": 1000
}
]
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}值的个数统计
"count_price": {
"value_count": {
"field": "price"
}
}实现having 效果
POST /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 200
},
{
"from": 200,
"to": 400
},
{
"from": 400,
"to": 1000
}
]
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
},
"having": {
"bucket_selector": {
"buckets_path": {
"avg_price": "average_price"
},
"script": {
"source": "params.avg_price >= 200 "
}
}
}
}
}
}
}玩转Elasticsearch零停机索引重建
说明
Elasticsearch是一个实时的分布式搜索引擎,为用户提供搜索服务,当我们决定存储某种数据时,在创 建索引的时候需要数据结构完整确定下来,与此同时索引的设定和很多固定配置将不能改变。当需要改 变数据结构时就需要重建索引,为此,Elasticsearch团队提供了辅助工具帮助开发人员进行索引重建。
零停机完成索引重建的三种方案。
外部数据导入方案
1)整体介绍
系统架构设计中,有关系型数据库用来存储数据,Elasticsearch在系统架构里起到查询加速的作用,如 果遇到索引重建的操作,待系统模块发布新版本后,可以从数据库将数据查询出来,重新灌到 Elasticsearch即可。
2)执行步骤
建议的功能方案:数据库 + MQ + 应用模块 + Elasticsearch,可以在MQ控制台发送MQ消息来触发重 导数据,按批次对数据进行导入,整个过程异步化处理,请求操作示意如下所示:
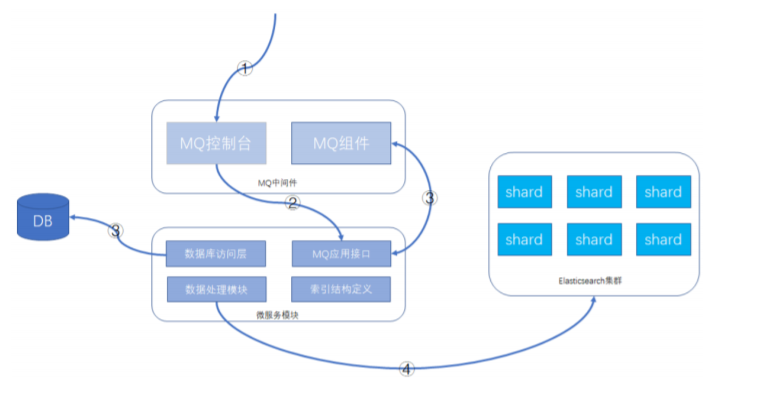
3)详细操作步骤:
- 通过MQ的web控制台或cli命令行,发送指定的MQ消息
- MQ消息被微服务模块的消费者消费,触发ES数据重新导入功能
- 微服务模块从数据库里查询数据的总数及批次信息,并将每个数据批次的分页信息重新发送给MQ 消息,分页信息包含查询条件和偏移量,此MQ消息还是会被微服务的MQ消息者接收处理。
- 微服务根据接收的查询条件和分页信息,从数据库获取到数据后,根据索引结构的定义,将数据组 装成ES支持的JSON格式,并执行bulk命令,将数据发送给Elasticsearch集群。
这样就可以完成索引的重建工作。
4)方案特点
MQ中间件的选型不做具体要求,常见的rabitmq、activemq、rocketmq等均可。
在微服务模块方面,提供MQ消息处理接口、数据处理模块需要事先开发的,一般是创建新的索引时, 配套把重建的功能也一起做好。整体功能共用一个topic,针对每个索引,有单独的结构定义和MQ消息 处理tag,代码尽可能复用。处理的批次大小需要根据实际的情况设置。
微服务模块实例会部署多个,数据是分批处理的,批次信息会一次性全部先发送给MQ,各个实例处理 的数据相互不重叠,利用MQ消息的异步处理机制,可以充分利用并发的优势,加快数据重建的速度。
5)方案缺点
- 对数据库造成读取压力,短时间内大量的读操作,会占用数据库的硬件资源,严重时可能引起数据 库性能下降。
- 网络带宽占用多,数据毕竟是从一个库传到另一个库,虽说是内网,但大量的数据传输带宽占用也 需要注意。
- 数据重建时间稍长,跟迁移的数据量大小有关。
基于scroll+bulk+索引别名方案
1)整体介绍
利用Elasticsearch自带的一些工具完成索引的重建工作,当然在方案实际落地时,可能也会依赖客户端 的一些功能,比如用Java客户端持续的做scroll查询、bulk命令的封装等。数据完全自给自足,不依赖 其他数据源。
2)执行步骤
假设原索引名称是book,新的索引名称为book_new,Java客户端使用别名book_alias连接 Elasticsearch,该别名指向原索引book。
1、若Java客户端没有使用别名,需要给客户端分配一个:PUT /book/_alias/book_alias
2、 新建索引book_new,将mapping信息,settings信息等按新的要求全部定义好。
3、使用scroll api将数据批量查询出来
为了使用 scroll,初始搜索请求应该在查询中指定 scroll 参数,这可以告诉 Elasticsearch 需要 保持搜索的上下文环境多久,1m 就是一分钟。
GET /book/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": ["_doc"],
"size": 2
}4、 采用bulk api将scoll查出来的一批数据,批量写入新索引
POST /_bulk
{ "index": { "_index": "book_new", "_id": "对应的id值" }}
{ 查询出来的数据值 }5、 反复执行修改后的步骤3和步骤4,查询一批导入一批,以后可以借助Java Client或其他语言的API 支持。
注意做3时需要指定上一次查询的 scroll_id
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "步骤三中查询出来的值"
}6、 切换别名book_alias到新的索引book_new上面,此时Java客户端仍然使用别名访问,也不需要修 改任何代码,不需要停机。
POST /_aliases
{
"actions": [
{ "remove": { "index": "book", "alias": "book_alias" }},
{ "add": { "index": "book_new", "alias": "book_alias" }}
]
}7、 验证别名查询的是否为新索引的数据
3)方案特点
在数据传输上基本自给自足,不依赖于其他数据源,Java客户端不需要停机等待数据迁移,网络传输占 用带宽较小。只是scroll查询和bulk提交这部分,数据量大时需要依赖一些客户端工具。
4)补充一点
在Java客户端或其他客户端访问Elasticsearch集群时,使用别名是一个好习惯。
Reindex API方案
Elasticsearch v6.3.1已经支持Reindex API,它对scroll、bulk做了一层封装,能够 对文档重建索引而不 需要任何插件或外部工具。
1)最基础的命令:
POST _reindex
{
"source": {
"index": "book"
},
"dest": {
"index": "book_new"
}
}响应结果:
{
"took": 180,
"timed_out": false,
"total": 4,
"updated": 0,
"created": 4,
"deleted": 0,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}注意: 如果不手动创建新索引book_new的mapping信息,那么Elasticsearch将启动自动映射模板对数 据进行类型映射,可能不是期望的类型,这点要注意一下。
2)version_type 属性
使用reindex api也是创建快照后再执行迁移的,这样目标索引的数据可能会与原索引有差异, version_type属性可以决定乐观锁并发处理的规则。
reindex api可以设置version_type属性,如下:
POST _reindex
{
"source": {
"index": "book"
},
"dest": {
"index": "book_new",
"version_type": "internal"
}
}version_type属性含义如下:
- internal:直接拷贝文档到目标索引,对相同的type、文档ID直接进行覆盖,默认值
- external:迁移文档到目标索引时,保留version信息,对目标索引中不存在的文档进行创建,已 存在的文档按version进行更新,遵循乐观锁机制。
3)op_type 属性和conflicts 属性
如果op_type设置为create,那么迁移时只在目标索引中创建ID不存在的文档,已存在的文档,会提示 错误,如下请求:
POST _reindex
{
"source": {
"index": "book"
},
"dest": {
"index": "book_new",
"op_type": "create"
}
}有错误提示的响应,节选部分:
{
"took": 11,
"timed_out": false,
"total": 5,
"updated": 0,
"created": 1,
"deleted": 0,
"batches": 1,
"version_conflicts": 4,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": [
{
"index": "book_new",
"type": "children",
"id": "2",
"cause": {
"type": "version_conflict_engine_exception",
"reason": "[children][2]: version conflict, document already exists
(current version [17])",
"index_uuid": "dODetUbATTaRL-p8DAEzdA",
"shard": "2",
"index": "book_new"
},
"status": 409
}
]
}如果加上"conflicts": "proceed"配置项,那么冲突信息将不展示,只展示冲突的文档数量,请求和响应 结果将变成这样:
请求:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "book"
},
"dest": {
"index": "book_new",
"op_type": "create"
}
}响应:
{
"took": 12,
"timed_out": false,
"total": 5,
"updated": 0,
"created": 1,
"deleted": 0,
"batches": 1,
"version_conflicts": 4,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}4)query支持
reindex api支持数据过滤、数据排序、size设置、_source选择等,也支持脚本执行,这里提供一个简 单示例:
POST _reindex
{
"size": 100,
"source": {
"index": "book",
"query": {
"term": {
"language": "english"
}
},
"sort": {
"likes": "desc"
}
},
"dest": {
"index": "book_new"
}
}小结
零停机索引重建操作的三个方案,从自研功能、scroll+bulk到reindex,我们作为Elasticsearch的使用 者,三个方案的参与度是逐渐弱化的,但稳定性却是逐渐上升的,我们需要清楚地去了解各个方案的优 劣,适宜的场景,然后根据实际的情况去权衡,哪个方案更适合我们的业务模型.
玩转Elasticsearch Suggester智能搜索建议
现代的搜索引擎,一般会具备"Suggest As You Type"功能,即在用户输入搜索的过程中,进行自动补全 或者纠错。 通过协助用户输入更精准的关键词,提高后续全文搜索阶段文档匹配的程度。例如在京东上 输入部分关键词,甚至输入拼写错误的关键词时,它依然能够提示出用户想要输入的内容:

如果自己亲手去试一下,可以看到京东在用户刚开始输入的时候是自动补全的,而当输入到一定长度, 如果因为单词拼写错误无法补全,就开始尝试提示相似的词。
那么类似的功能在Elasticsearch里如何实现呢? 答案就在Suggesters API。 Suggesters基本的运作原 理是将输入的文本分解为token,然后在索引的字典里查找相似的term并返回。 根据使用场景的不同, Elasticsearch里设计了4种类别的Suggester,分别是:
- Term Suggester
- Phrase Suggester
- Completion Suggester
- Context Suggester
在官方的参考文档里,对这4种Suggester API都有比较详细的介绍,下面的案例将在Elasticsearch 7.x 上通过示例讲解Suggester的基础用法,希望能帮助部分国内开发者快速用于实际项目开发。
首先来看一个Term Suggester的示例:
准备一个叫做blogs的索引,配置一个text字段
PUT /blogs/
{
"mappings": {
"properties": {
"body": {
"type": "text"
}
}
}
}通过bulk api写入几条文档
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs" } }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs" } }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs" } }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs" } }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs" } }
{ "body": "elk rocks"}
{ "index" : { "_index" : "blogs"} }
{ "body": "elasticsearch is rock solid"} 此时blogs索引里已经有一些文档了,可以进行下一步的探索。为帮助理解,我们先看看哪些term会存 在于词典里。
将输入的文本分析一下:
POST _analyze
{
"text": [
"Lucene is cool",
"Elasticsearch builds on top of lucene",
"Elasticsearch rocks",
"Elastic is the company behind ELK stack",
"elk rocks",
"elasticsearch is rock solid"
]
} 这些分出来的token都会成为词典里一个term,注意有些token会出现多次,因此在倒排索引里记录的 词频会比较高,同时记录的还有这些token在原文档里的偏移量和相对位置信息。
执行一次suggester搜索看看效果:
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne rock",
"term": {
"suggest_mode": "missing",
"field": "body"
}
}
}
}suggest就是一种特殊类型的搜索,DSL内部的"text"指的是api调用方提供的文本,也就是通常用户界 面上用户输入的内容。这里的lucne是错误的拼写,模拟用户输入错误。 "term"表示这是一个term suggester。 "field"指定suggester针对的字段,另外有一个可选的"suggest_mode"。 范例里 的"missing"实际上就是缺省值,它是什么意思?有点挠头... 还是先看看返回结果吧:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits":
},
"suggest": {
"my-suggestion": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options":
}
]
}
}在返回结果里"suggest" -> "my-suggestion"部分包含了一个数组,每个数组项对应从输入文本分解出 来的token(存放在"text"这个key里)以及为该token提供的建议词项(存放在options数组里)。 示例 里返回了"lucne","rock"这2个词的建议项(options),其中"rock"的options是空的,表示没有可以建议 的选项,为什么? 上面提到了,我们为查询提供的suggest mode是"missing",由于"rock"在索引的词典 里已经存在了,够精准,就不建议啦。 只有词典里找不到词,才会为其提供相似的选项。
如果将"suggest_mode"换成"popular"会是什么效果?
尝试一下,重新执行查询,返回结果里"rock"这个词的option不再是空的,而是建议为rocks。
"suggest": {
"my-suggestion": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options": [
{
"text": "rocks",
"score": 0.75,
"freq": 2
}
]
}
]
}回想一下,rock和rocks在索引词典里都是有的。 不难看出即使用户输入的token在索引的词典里已经 有了,但是因为存在一个词频更高的相似项,这个相似项可能是更合适的,就被挑选到options里了。 最后还有一个"always" mode,其含义是不管token是否存在于索引词典里都要给出相似项。
有人可能会问,两个term的相似性是如何判断的? ES使用了一种叫做Levenstein edit distance的算 法,其核心思想就是一个词改动多少个字符就可以和另外一个词一致。 Term suggester还有其他很多 可选参数来控制这个相似性的模糊程度,这里就不一一赘述了。
Phrase suggester在Term suggester的基础上,会考量多个term之间的关系,比如是否同时出现在索 引的原文里,相邻程度,以及词频等等。看个范例就比较容易明白了:
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne and elasticsear rock",
"phrase": {
"field": "body",
"highlight": {
"pre_tag": "<em>",
"post_tag": "</em>"
}
}
}
}
}返回结果:
"suggest": {
"my-suggestion": [
{
"text": "lucne and elasticsear rock",
"offset": 0,
"length": 26,
"options": [
{
"text": "lucene and elasticsearch rock",
"highlighted": "<em>lucene</em> and <em>elasticsearch</em> rock",
"score": 0.004993905
},
{
"text": "lucne and elasticsearch rock",
"highlighted": "lucne and <em>elasticsearch</em> rock",
"score": 0.0033391973
},
{
"text": "lucene and elasticsear rock",
"highlighted": "<em>lucene</em> and elasticsear rock",
"score": 0.0029183894
}
]
}
]
}options直接返回一个phrase列表,由于加了highlight选项,被替换的term会被高亮。因为lucene和 elasticsearch曾经在同一条原文里出现过,同时替换2个term的可信度更高,所以打分较高,排在第一 位返回。Phrase suggester有相当多的参数用于控制匹配的模糊程度,需要根据实际应用情况去挑选和 调试。
下面来谈一下Completion Suggester,它主要针对的应用场景就是"Auto Completion"。 此场景下用户 每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况 下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并 非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引, FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是 Completion Suggester的局限所在。
为了使用Completion Suggester,字段的类型需要专门定义如下:
PUT /blogs_completion/
{
"mappings": {
"properties": {
"body": {
"type": "completion"
}
}
}
}用bulk API索引点数据:
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "the elk stack rocks"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "elasticsearch is rock solid"}查找:
POST /blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}结果:
"suggest" : {
"blog-suggest" : [
{
"text" : "elastic i",
"offset" : 0,
"length" : 9,
"options" : [
{
"text" : "Elastic is the company behind ELK stack",
"_index" : "blogs_completion",
"_type" : "_doc",
"_id" : "7WIhOnQB-DBpPI60CSK-",
"_score" : 1.0,
"_source" : {
"body" : "Elastic is the company behind ELK stack"
}
}
]
}
]
}
}值得注意的一点是Completion Suggester在索引原始数据的时候也要经过analyze阶段,取决于选用的 analyzer不同,某些词可能会被转换,某些词可能被去除,这些会影响FST编码结果,也会影响查找匹 配的效果。
比如我们删除上面的索引,重新设置索引的mapping,将analyzer更改为"english":
PUT /blogs_completion/
{
"mappings": {
"properties": {
"body": {
"type": "completion",
"analyzer":"english"
}
}
}
}
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs_completion" } }
{ "body": "the elk stack rocks"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "elasticsearch is rock solid"}bulk api索引同样的数据后,执行下面的查询:
POST /blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
} 居然没有匹配结果了,多么费解! 原来我们用的english analyzer会剥离掉stop word,而is就是其中 一个,被剥离掉了!
用analyze api测试一下:
POST _analyze
{
"text": "elasticsearch is rock solid",
"analyzer":"english"
}
会发现只有3个token:
{
"tokens": [
{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "rock",
"start_offset": 17,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "solid",
"start_offset": 22,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 3
}
]
}FST(Finite StateTransducers)只编码了这3个token,并且默认的还会记录他们在文档中的位置和分隔 符。 用户输入"elastic i"进行查找的时候,输入被分解成"elastic"和"i",FST没有编码这个“i” , 匹配失 败。
好吧,如果你现在还足够清醒的话,试一下搜索"elastic is",会发现又有结果,why? 因为这次输入的 text经过english analyzer的时候is也被剥离了,只需在FST里查询"elastic"这个前缀,自然就可以匹配到 了。
其他能影响completion suggester结果的,还有 如"preserve_separators","preserve_position_increments"等等mapping参数来控制匹配的模糊程 度。以及搜索时可以选用Fuzzy Queries,使得上面例子里的"elastic i"在使用english analyzer的情况下 依然可以匹配到结果。
"preserve_separators": false, 这个设置为false,将忽略空格之类的分隔符
"preserve_position_increments": true,如果建议词第一个词是停用词,并且我们使用了过滤停用词的分析器,需要将此设置为false。 因此用好Completion Sugester并不是一件容易的事,实际应用开发过程中,需要根据数据特性和业务 需要,灵活搭配analyzer和mapping参数,反复调试才可能获得理想的补全效果。
回到篇首京东或者百度搜索框的补全/纠错功能,如果用ES怎么实现呢?我能想到的一个的实现方式: 在用户刚开始输入的过程中,使用Completion Suggester进行关键词前缀匹配,刚开始匹配项会比较 多,随着用户输入字符增多,匹配项越来越少。如果用户输入比较精准,可能Completion Suggester的 结果已经够好,用户已经可以看到理想的备选项了。
如果Completion Suggester已经到了零匹配,那么可以猜测是否用户有输入错误,这时候可以尝试一下 Phrase Suggester。如果Phrase Suggester没有找到任何option,开始尝试term Suggester。
精准程度上(Precision)看: Completion > Phrase > term, 而召回率上(Recall)则反之。从性能上看, Completion Suggester是最快的,如果能满足业务需求,只用Completion Suggester做前缀匹配是最 理想的。 Phrase和Term由于是做倒排索引的搜索,相比较而言性能应该要低不少,应尽量控制 suggester用到的索引的数据量,最理想的状况是经过一定时间预热后,索引可以全量map到内存。
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
从一个大规模数据集合中检索文档时,可把文档分成四组:
- 系统检索到的相关文档(A)
- 系统检索到的不相关文档(B)
- 相关但是系统没有检索到的文档(C)
- 不相关且没有被系统检索到的文档(D)
则:
- 召回率R:用实际检索到相关文档数作为分子,所有相关文档总数作为分母,即R = A / ( A + C )
- 精度P:用实际检索到相关文档数作为分子,所有检索到的文档总数作为分母,即P = A / ( A + B )
举例:一个数据库有 1000 个文档,其中有 50 个文档符合相关定义的问题,系统检索到 75 个文档,但
其中只有 45 个文档被检索出。
精度:P=45/75=60%。
召回率:R=45/50=90%。Context Suggester
- Completion Suggester 的扩展
- 可以在搜索中加入更多的上下文信息,然后根据不同的上下文信息,对相同的输入,比如"star", 提供不同的建议值,比如:
- 咖啡相关:starbucks
- 电影相关:star wars
玩转Elasticsearch Java Client
说明
ES提供多种不同的客户端:
- TransportClient ES提供的传统客户端,官方计划8.0版本删除此客户端。
- RestClient RestClient是官方推荐使用的,它包括两种:Java Low Level REST Client和 Java High Level REST Client。 ES在6.0之后提供 Java High Level REST Client, 两种客户端官方更推荐使用 Java High Level REST Client, 使用时加入对应版本的依赖即可。
SpringBoot 中使用 RestClient
1)配置 pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.3.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.3.0</version>
</dependency>
</dependencies>2) application.yml文件配置
lagouelasticsearch:
elasticsearch:
hostlist: 192.168.211.138:9200 #多个结点中间用逗号分隔3)配置类
@Configuration
public class ElasticsearchConfig {
@Value("${lagouelasticsearch.elasticsearch.hostlist}")
private String hostlist;
@Bean
public RestHighLevelClient restHighLevelClient(){
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0],
Integer.parseInt(item.split(":")[1]), "http");
}
//创建RestHighLevelClient客户端
return new RestHighLevelClient(RestClient.builder(httpHostArray));
}
//项目主要使用RestHighLevelClient,对于低级的客户端暂时不用
@Bean
public RestClient restClient(){
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0],
Integer.parseInt(item.split(":")[1]), "http");
}
return RestClient.builder(httpHostArray).build();
}4) 编写启动类
package com.lagou;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ESApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(ESApplication.class, args);
}
}5)索引操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class TestIndex {
@Autowired
RestHighLevelClient client;
@Autowired
RestClient restClient;
//创建索引库
/*
PUT /elasticsearch_test
{
"settings": {},
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "ik_max_word"
},
"name": {
"type": "keyword"
},
"pic": {
"type": "text",
"index": false
},
"studymodel": {
"type": "keyword"
}
}
}
}
*/
@Test
public void testCreateIndex() throws IOException {
//创建索引对象
CreateIndexRequest createIndexRequest = new
CreateIndexRequest("elasticsearch_test");
//设置参数
createIndexRequest.settings(Settings.builder().put("number_of_shards","1").put(
"number_of_replicas","0"));
// 指定映射
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("properties")
.startObject()
.field("studymodel").startObject().field("index",
"true").field("type", "keyword").endObject()
.field("name").startObject().field("index",
"true").field("type", "integer").endObject()
.field("description").startObject().field("index",
"true").field("type", "text").field("analyzer", "ik_max_word").endObject()
.field("pic").startObject().field("index",
"false").field("type", "text").endObject()
.endObject()
.endObject();
createIndexRequest.mapping("doc",builder);
/*指定映射
createIndexRequest.mapping("doc"," {\n" +
" \t\"properties\": {\n" +
" \"studymodel\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\":\"ik_max_word\" \n" +
" },\n" +
" \"pic\":{\n" +
" \"type\":\"text\",\n" +
" \"index\":false\n" +
" }\n" +
" \t}\n" +
"}", XContentType.JSON);
*/
//操作索引的客户端
IndicesClient indices = client.indices();
//执行创建索引库
//CreateIndexResponse createIndexResponse =
indices.create(createIndexRequest, RequestOptions.DEFAULT);
CreateIndexResponse createIndexResponse =
indices.create(createIndexRequest,RequestOptions.DEFAULT);
//得到响应
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
//删除索引库
@Test
public void testDeleteIndex() throws IOException {
//删除索引的请求对象
DeleteIndexRequest deleteIndexRequest = new
DeleteIndexRequest("elasticsearch_test");
//操作索引的客户端
IndicesClient indices = client.indices();
//执行删除索引
AcknowledgedResponse delete = indices.delete(deleteIndexRequest,
RequestOptions.DEFAULT);
//得到响应
boolean acknowledged = delete.isAcknowledged();
System.out.println(acknowledged);
}
//添加文档
/*
POST /elasticsearch_test/_doc/1
{
"name": "spring cloud实战",
"description": "本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基
础入门 3.实战Spring Boot 4.注册中心eureka。",
"studymodel":"201001",
"timestamp": "2020-08-22 20:09:18",
"price": 5.6
}
*/
@Test
public void testAddDoc() throws IOException {
//创建索引请求对象
IndexRequest indexRequest = new
IndexRequest("elasticsearch_test","doc");
indexRequest.id("1");
//文档内容 准备json数据
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("name", "spring cloud实战");
jsonMap.put("description", "本课程主要从四个章节进行讲解: 1.微服务架构入门
2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。");
jsonMap.put("studymodel", "201001");
SimpleDateFormat dateFormat =new SimpleDateFormat("yyyy-MM-dd
HH:mm:ss");
jsonMap.put("timestamp", dateFormat.format(new Date()));
jsonMap.put("price", 5.6f);
indexRequest.source(jsonMap);
//通过client进行http的请求
IndexResponse indexResponse =
client.index(indexRequest,RequestOptions.DEFAULT);
DocWriteResponse.Result result = indexResponse.getResult();
System.out.println(result);
}
}
//查询文档
@Test
public void testGetDoc() throws IOException {
//查询请求对象
GetRequest getRequest = new GetRequest("elasticsearch_test","2");
GetResponse getResponse = client.get(getRequest,RequestOptions.DEFAULT);
//得到文档的内容
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
System.out.println(sourceAsMap);
}6) 其它搜索操作
//搜索全部记录
/*
GET /elasticsearch_test/_search
{
"query":{
"match_all":{}
}
}
*/
@Test
public void testSearchAll() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("elasticsearch_test");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式
//matchAllQuery搜索全部
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]
{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
TotalHits totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd
HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String)
sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
//TermQuery
@Test
public void testTermQuery() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("elasticsearch_test");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//搜索方式
//termQuery
searchSourceBuilder.query(QueryBuilders.termQuery("name","spring"));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]
{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse =
client.search(searchRequest,RequestOptions.DEFAULT);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
TotalHits totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd
HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String)
sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
//分页查询
@Test
public void testSearchPage() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("elasticsearch_test");
//指定类型
searchRequest.types("doc");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页参数
//页码
int page = 1;
//每页记录数
int size = 2;
//计算出记录起始下标
int from = (page-1)*size;
searchSourceBuilder.from(from);//起始记录下标,从0开始
searchSourceBuilder.size(size);//每页显示的记录数
//搜索方式
//matchAllQuery搜索全部
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]
{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse =
client.search(searchRequest,RequestOptions.DEFAULT);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
TotalHits totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd
HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String)
sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
//TermQuery 分页
@Test
public void testTermQuery() throws IOException, ParseException {
//搜索请求对象
SearchRequest searchRequest = new SearchRequest("elasticsearch_test");
//搜索源构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页参数
//页码
int page = 1;
//每页记录数
int size = 2;
//计算出记录起始下标
int from = (page-1)*size;
searchSourceBuilder.from(from);//起始记录下标,从0开始
searchSourceBuilder.size(size);//每页显示的记录数
//搜索方式
//termQuery
searchSourceBuilder.query(QueryBuilders.termQuery("name","spring"));
//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
searchSourceBuilder.fetchSource(new String[]
{"name","studymodel","price","timestamp"},new String[]{});
//向搜索请求对象中设置搜索源
searchRequest.source(searchSourceBuilder);
//执行搜索,向ES发起http请求
SearchResponse searchResponse =
client.search(searchRequest,RequestOptions.DEFAULT);
//搜索结果
SearchHits hits = searchResponse.getHits();
//匹配到的总记录数
TotalHits totalHits = hits.getTotalHits();
//得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
//日期格式化对象
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd
HH:mm:ss");
for(SearchHit hit:searchHits){
//文档的主键
String id = hit.getId();
//源文档内容
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
//由于前边设置了源文档字段过虑,这时description是取不到的
String description = (String) sourceAsMap.get("description");
//学习模式
String studymodel = (String) sourceAsMap.get("studymodel");
//价格
Double price = (Double) sourceAsMap.get("price");
//日期
Date timestamp = dateFormat.parse((String)
sourceAsMap.get("timestamp"));
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}