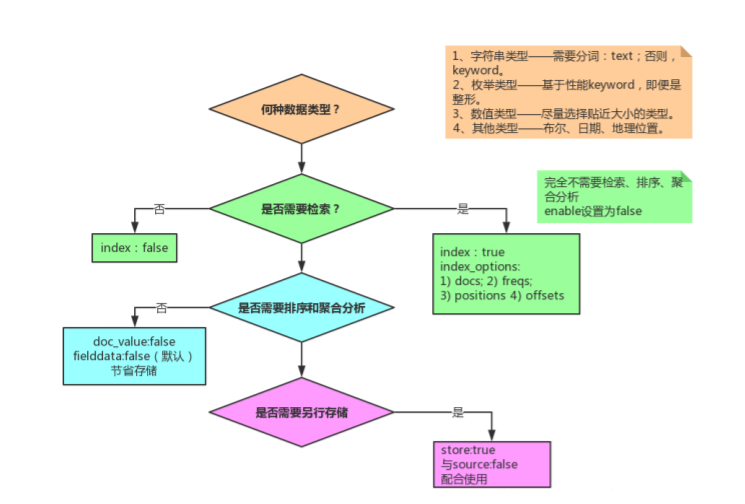
映射高级
地理坐标点数据类型
地理坐标点
地理坐标点是指地球表面可以用经纬度描述的一个点。 地理坐标点可以用来计算两个坐标间的距离,还 可以判断一个坐标是否在一个区域中。地理坐标点需要显式声明对应字段类型为 geo_point :
示例
PUT /company-locations
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"location": {
"type": "geo_point"
}
}
}
}经纬度坐标格式
如上例, location 字段被声明为 geo_point 后,我们就可以索引包含了经纬度信息的文档了。 经纬 度信息的形式可以是字符串、数组或者对象
# 字符串形式
PUT /company-locations/_doc/1
{
"name":"NetEase",
"location":"40.715,74.011"
}
# 对象形式
PUT /company-locations/_doc/2
{
"name":"Sina",
"location":{
"lat":40.722,
"lon":73.989
}
}
# 数组形式
PUT /company-locations/_doc/3
{
"name":"Baidu",
"location":[73.983,40.719]
}注意
字符串形式以半角逗号分割,如 "lat,lon"
对象形式显式命名为 lat 和 lon
数组形式表示为 [lon,lat]
通过地理坐标点过滤
有四种地理坐标点相关的过滤器 可以用来选中或者排除文档

geo_bounding_box查询
这是目前为止最有效的地理坐标过滤器了,因为它计算起来非常简单。 你指定一个矩形的顶部 , 底部 , 左边界和右边界,然后过滤器只需判断坐标的经度是否在左右边界之间,纬度是否在上下边 界之间
然后可以使用 geo_bounding_box 过滤器执行以下查询
GET /company-locations/_search
{
"query": {
"bool" : {
"must" : {
"match_all" : {}
},
"filter" : {
"geo_bounding_box" : {
"location" : {
"top_left" : {
"lat" : 40.73,
"lon" : 71.12
},
"bottom_right" : {
"lat" : 40.01,
"lon" : 74.1
}
}
}
}
}
}
}location这些坐标也可以用 bottom_left 和 top_right 来表示
geo_distance
过滤仅包含与地理位置相距特定距离内的匹配的文档。假设以下映射和索引文档
然后可以使用 geo_distance 过滤器执行以下查询
GET /company-locations/_search
{
"query": {
"bool" : {
"must" : {
"match_all" : {}
},
"filter" : {
"geo_distance" : {
"distance" : "200km",
"location" : {
"lat" : 40,
"lon" : 70
}
}
}
}
}
}动态映射
Elasticsearch在遇到文档中以前未遇到的字段,可以使用dynamic mapping(动态映射机制) 来确定 字段的数据类型并自动把新的字段添加到类型映射。
Elastic的动态映射机制可以进行开关控制,通过设置mappings的dynamic属性,dynamic有如下设置 项
- true:遇到陌生字段就执行dynamic mapping处理机制
- false:遇到陌生字段就忽略
- strict:遇到陌生字段就报错
# 设置为报错
PUT /user
{
"settings":{
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings":{
"dynamic": "strict",
"properties": {
"name": {"type": "text"},
"address": {"type": "object", "dynamic": true}
}
}
}
# 插入以下文档,将会报错
# user索引层设置dynamic是strict,在user层内设置age将报错
# 在address层设置dynamic是ture,将动态映射生成字段
PUT /user/_doc/1
{
"name": "lisi",
"age": "20",
"address": {
"province": "beijing",
"city": "beijing"
}
}
PUT /user
{
"settings":{
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings":{
"dynamic": true,
"properties": {
"name": {"type": "text"},
"address": {"type": "object", "dynamic": true}
}
}
}自定义动态映射
如果你想在运行时增加新的字段,你可能会启用动态映射。 然而,有时候,动态映射 规则 可能不太智 能。幸运的是,我们可以通过设置去自定义这些规则,以便更好的适用于你的数据。
日期检测
当 Elasticsearch 遇到一个新的字符串字段时,它会检测这个字段是否包含一个可识别的日期,比如 2014-01-01 如果它像日期,这个字段就会被作为 date 类型添加。否则,它会被作为 string 类型添加。 有些时候这个行为可能导致一些问题。想象下,你有如下这样的一个文档:
{ "note": "2014-01-01" }
假设这是第一次识别 note 字段,它会被添加为 date 字段。但是如果下一个文档像这样: { "note": "Logged out" }
这显然不是一个日期,但为时已晚。这个字段已经是一个日期类型,这个 不合法的日期 将会造成一个 异常。
日期检测可以通过在根对象上设置 date_detection 为 false 来关闭
UT /my_index/_doc/1
{ "note": "2014-01-01" }
PUT /my_index/_doc/1
{ "note": "Logged out" }
PUT /my_index
{
"mappings": {
"date_detection": false
}
}使用这个映射,字符串将始终作为 string 类型。如果需要一个 date 字段,必须手动添加。 Elasticsearch 判断字符串为日期的规则可以通过 dynamic_date_formats setting 来设置。
PUT /my_index
{
"mappings": {
"dynamic_date_formats": "MM/dd/yyyy"
}
}
PUT /my_index/_doc/1
{ "note": "2014-01-01" }
PUT /my_index/_doc/1
{ "note": "01/01/2014" }dynamic_templates
使用 dynamic_templates 可以完全控制新生成字段的映射,甚至可以通过字段名称或数据类型来应用 不同的映射。每个模板都有一个名称,你可以用来描述这个模板的用途,一个 mapping 来指定映射应 该怎样使用,以及至少一个参数 (如 match) 来定义这个模板适用于哪个字段。
模板按照顺序来检测;第一个匹配的模板会被启用。例如,我们给 string 类型字段定义两个模板:
es :以 _es 结尾的字段名需要使用 spanish 分词器。
en :所有其他字段使用 english 分词器。
我们将 es 模板放在第一位,因为它比匹配所有字符串字段的 en 模板更特殊:
PUT /my_index2
{
"mappings": {
"dynamic_templates": [
{
"es": {
"match": "*_es",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "spanish"
}
}
},
{
"en": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "english"
}
}
}
]
}
}PUT /my_index2/_doc/1
{
"name_es":"testes",
"name":"es"
} 1)匹配字段名以 _es 结尾的字段
2)匹配其他所有字符串类型字段
match_mapping_type 允许你应用模板到特定类型的字段上,就像有标准动态映射规则检测的一样 (例 如 string 或 long)
match参数只匹配字段名称,path_match 参数匹配字段在对象上的完整路径,所以 address.*.name 将匹配这样的字段
{
"address": {
"city": {
"name": "New York"
}
}
}Query DSL
Elasticsearch提供了基于JSON的完整查询DSL(Domain Specific Language 特定域的语言)来定义查 询。将查询DSL视为查询的AST(抽象语法树),它由两种子句组成:
- 叶子查询子句
叶子查询子句 在特定域中寻找特定的值,如 match,term或 range查询。 - 复合查询子句
复合查询子句包装其他叶子查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或 dis_max查询),或更改其行为(例如 constant_score查询)。
我们在使用ElasticSearch的时候,避免不了使用DSL语句去查询,就像使用关系型数据库的时候要学会 SQL语法一样。如果我们学习好了DSL语法的使用,那么在日后使用和使用Java Client调用时候也会变 得非常简单。
基本语法
POST /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:
- 例如: match_all , match , term , range 等等
- 查询条件:查询条件会根据类型的不同,写法也有差异,后面详细讲解
查询所有(match_all query)
示例
POST /lagou-company-index/_search
{
"query":{
"match_all": {}
}
}- query :代表查询对象
- match_all :代表查询所有
结果
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
全文搜索(full-text query)
全文搜索能够搜索已分析的文本字段,如电子邮件正文,商品描述等。使用索引期间应用于字段的同一 分析器处理查询字符串。全文搜索的分类很多 几个典型的如下:
匹配搜索(match query)
全文查询的标准查询,它可以对一个字段进行模糊、短语查询。 match queries 接收 text/numerics/dates, 对它们进行分词分析, 再组织成一个boolean查询。可通过operator 指定bool组 合操作(or、and 默认是 or )。
现在,索引库中有2部手机,1台电视;
PUT /lagou-property
{
"settings": {},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword"
},
"price": {
"type": "float"
}
}
}
}
POST /lagou-property/_doc/
{
"title": "小米电视4A",
"images": "http://image.lagou.com/12479122.jpg",
"price": 4288
}
POST /lagou-property/_doc/
{
"title": "小米手机",
"images": "http://image.lagou.com/12479622.jpg",
"price": 2699
}
POST /lagou-property/_doc/
{
"title": "华为手机",
"images": "http://image.lagou.com/12479922.jpg",
"price": 5699
} or关系
match 类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
POST /lagou-property/_search
{
"query":{
"match":{
"title":"小米电视4A"
}
}
}结果:
{
"took" : 695,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.8330114,
"hits" : [
{
"_index" : "lagou-property",
"_type" : "_doc",
"_id" : "UKcMCnQB7BOR-NcQDHX4",
"_score" : 2.8330114,
"_source" : {
"title" : "小米电视4A",
"images" : "http://image.lagou.com/12479122.jpg",
"price" : 4288
}
},
{
"_index" : "lagou-property",
"_type" : "_doc",
"_id" : "UacMCnQB7BOR-NcQGnUb",
"_score" : 0.52354836,
"_source" : {
"title" : "小米手机",
"images" : "http://image.lagou.com/12479622.jpg",
"price" : 2699
}
}
]
}
}在上面的案例中,不仅会查询到电视,而且与小米相关的都会查询到,多个词之间是 or 的关系。
and关系
某些情况下,我们需要更精确查找,我们希望这个关系变成 and ,可以这样做:
POST /lagou-property/_search
{"query": {"match": {
"title": {"query": "小米电视4A","operator": "and"}
}}}
结果:
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.8330114,
"hits" : [
{
"_index" : "lagou-property",
"_type" : "_doc",
"_id" : "UKcMCnQB7BOR-NcQDHX4",
"_score" : 2.8330114,
"_source" : {
"title" : "小米电视4A",
"images" : "http://image.lagou.com/12479122.jpg",
"price" : 4288
}
}
]
}
}本例中,只有同时包含 小米 和 电视 的词条才会被搜索到。
短语搜索(match phrase query)
match_phrase 查询用来对一个字段进行短语查询,可以指定 analyzer、slop移动因子
GET /lagou-property/_search
{
"query": {
"match_phrase": {
"title": "小米电视"
}
}
}
GET /lagou-property/_search
{
"query": {
"match_phrase": {
"title": "小米 4A"
}
}
}
GET /lagou-property/_search
{
"query": {
"match_phrase": {
"title": {
"query": "小米 4A",
"slop": 2
}
}
}
}query_string 查询
Query String Query提供了无需指定某字段而对文档全文进行匹配查询的一个高级查询,同时可以指定在 哪些字段上进行匹配。
# 默认 和 指定字段
GET /lagou-property/_search
{
"query": {
"query_string" : {
"query" : "2699"
}
}
}
GET /lagou-property/_search
{
"query": {
"query_string" : {
"query" : "2699",
"default_field" : "title"
}
}
}
# 逻辑查询
GET /lagou-property/_search
{
"query": {
"query_string" : {
"query" : "手机 OR 小米",
"default_field" : "title"
}
}
}
GET /lagou-property/_search
{
"query": {
"query_string" : {
"query" : "手机 AND 小米",
"default_field" : "title"
}
}
}
# 模糊查询
GET /lagou-property/_search
{
"query": {
"query_string" : {
"query" : "大米~1",
"default_field" : "title"
}
}
}
# 多字段支持
GET /lagou-property/_search
{
"query": {
"query_string" : {
"query":"2699",
"fields": [ "title","price"]
}
}
}
多字段匹配搜索(multi match query)
如果你需要在多个字段上进行文本搜索,可用multi_match 。multi_match在 match的基础上支持对多 个字段进行文本查询。
GET /lagou-property/_search
{
"query": {
"multi_match" : {
"query":"2699",
"fields": [ "title","price"]
}
}
}还可以使用*匹配多个字段:
GET /lagou-property/_search
{
"query": {
"multi_match" : {
"query":"http://image.lagou.com/12479622.jpg",
"fields": [ "title","ima*"]
}
}
}词条级搜索(term-level queries)
可以使用term-level queries根据结构化数据中的精确值查找文档。结构化数据的值包括日期范围、IP 地址、价格或产品ID。
与全文查询不同,term-level queries不分析搜索词。相反,词条与存储在字段级别中的术语完全匹 配。
PUT /book
{
"settings": {},
"mappings" : {
"properties" : {
"description" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"name" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"price" : {
"type" : "float"
},
"timestamp" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
PUT /book/_doc/1
{
"name": "lucene",
"description": "Lucene Core is a Java library providing powerful indexing and
search features, as well as spellchecking, hit highlighting and advanced
analysis/tokenization capabilities. The PyLucene sub project provides Python
bindings for Lucene Core. ",
"price":100.45,
"timestamp":"2020-08-21 19:11:35"
}
PUT /book/_doc/2
{
"name": "solr",
"description": "Solr is highly scalable, providing fully fault tolerant
distributed indexing, search and analytics. It exposes Lucenes features through
easy to use JSON/HTTP interfaces or native clients for Java and other
languages.",
"price":320.45,
"timestamp":"2020-07-21 17:11:35"
}
PUT /book/_doc/3
{
"name": "Hadoop",
"description": "The Apache Hadoop software library is a framework that allows
for the distributed processing of large data sets across clusters of computers
using simple programming models.",
"price":620.45,
"timestamp":"2020-08-22 19:18:35"
}
PUT /book/_doc/4
{
"name": "ElasticSearch",
"description": "Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力
的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条
款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜
索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache
Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢
迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。",
"price":999.99,
"timestamp":"2020-08-15 10:11:35"
}词条搜索(term query)
term 查询用于查询指定字段包含某个词项的文档
POST /book/_search
{
"query": {
"term" : { "name" : "solr" }
}
}词条集合搜索(terms query)
terms 查询用于查询指定字段包含某些词项的文档
GET /book/_search
{
"query": {
"terms" : { "name" : ["solr", "elasticsearch"]}
}
}范围搜索(range query)
- gte:大于等于
- gt:大于
- lte:小于等于
- lt:小于
- boost:查询权重
GET /book/_search
{
"query": {
"range" : {
"price" : {
"gte" : 10,
"lte" : 200,
"boost" : 2.0
}
}
}
}
GET /book/_search
{
"query": {
"range" : {
"timestamp" : {
"gte" : "now-2d/d",
"lt" : "now/d"
}
}
}
}
GET book/_search
{
"query": {
"range" : {
"timestamp" : {
"gte": "18/08/2020",
"lte": "2021",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}不为空搜索(exists query)
查询指定字段值不为空的文档。相当 SQL 中的 column is not null
GET /book/_search
{
"query": {
"exists" : { "field" : "price" }
}
}词项前缀搜索(prefix query)
GET /book/_search
{ "query": {
"prefix" : { "name" : "so" }
}
}通配符搜索(wildcard query)
GET /book/_search
{
"query": {
"wildcard" : { "name" : "so*r" }
}
}
GET /book/_search
{
"query": {
"wildcard": {
"name": {
"value": "lu*",
"boost": 2
}
}
}
}正则搜索(regexp query)
regexp允许使用正则表达式进行term查询.注意regexp如果使用不正确,会给服务器带来很严重的性能 压力。比如.*开头的查询,将会匹配所有的倒排索引中的关键字,这几乎相当于全表扫描,会很慢。因 此如果可以的话,最好在使用正则前,加上匹配的前缀。
GET /book/_search
{
"query": {
"regexp":{
"name": "s.*"
}
}
}
GET /book/_search
{
"query": {
"regexp":{
"name":{
"value":"s.*",
"boost":1.2
}
}
}
}模糊搜索(fuzzy query)
GET /book/_search
{
"query": {
"fuzzy" : { "name" : "so" }
}
}
GET /book/_search
{
"query": {
"fuzzy" : {
"name" : {
"value": "so",
"boost": 1.0,
"fuzziness": 2
}
}
}
}
GET /book/_search
{
"query": {
"fuzzy" : {
"name" : {
"value": "sorl",
"boost": 1.0,
"fuzziness": 2
}
}
}
}ids搜索(id集合查询)
GET /book/_search
{
"query": {
"ids" : {
"type" : "_doc",
"values" : ["1", "3"]
}
}
}复合搜索(compound query)
1) constant_score query
用来包装另一个查询,将查询匹配的文档的评分设为一个常值
GET /book/_search
{
"query": {
"term" : { "description" : "solr"}
}
}
GET /book/_search
{
"query": {
"constant_score" : {
"filter" : {
"term" : { "description" : "solr"}
},
"boost" : 1.2
}
}
}2) 布尔搜索(bool query)
bool 查询用bool操作来组合多个查询字句为一个查询。 可用的关键字:
- must:必须满足
- filter:必须满足,但执行的是filter上下文,不参与、不影响评分
- should:或
- must_not:必须不满足,在filter上下文中执行,不参与、不影响评分
POST /book/_search
{
"query": {
"bool" : {
"must" : {
"match" : { "description" : "java" }
},
"filter": {
"term" : { "name" : "solr" }
},
"must_not" : {
"range" : {
"price" : { "gte" : 200, "lte" : 300 }
}
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}minimum_should_match代表了最小匹配精度,如果设置minimum_should_match=1,那么should 语句中至少需要有一个条件满足。
排序
相关性评分排序
默认情况下,返回的结果是按照 相关性 进行排序的——最相关的文档排在最前。 在本章的后面部 分,我们会解释 相关性 意味着什么以及它是如何计算的, 不过让我们首先看看 sort 参数以及如 何使用它。
为了按照相关性来排序,需要将相关性表示为一个数值。在 Elasticsearch 中, 相关性得分 由一 个浮点数进行表示,并在搜索结果中通过 _score 参数返回, 默认排序是 _score 降序,按照相 关性评分升序排序如下
POST /book/_search
{
"query": {
"match": {"description":"solr"}
}
}
POST /book/_search
{
"query": {
"match": {"description":"solr"}
},
"sort": [
{"_score": {"order": "asc"}}
]
}字段值排序
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{"price": {"order": "desc"}}
]
}多级排序
假定我们想要结合使用 price和 _score(得分) 进行查询,并且匹配的结果首先按照价格排序, 然后按照相关性得分排序:
POST /book/_search
{
"query":{
"match_all":{}
},
"sort": [
{ "price": { "order": "desc" }},
{ "timestamp": { "order": "desc" }}
]
}分页
Elasticsearch中实现分页的语法非常简单:
POST /book/_search
{
"query": {
"match_all": {}
},
"size": 2,
"from": 0
}
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{"price": {"order": "desc"}}
],
"size": 2,
"from": 2
} size:每页显示多少条
from:当前页起始索引, int start = (pageNum - 1) * size
高亮
Elasticsearch中实现高亮的语法比较简单:
POST /book/_search
{
"query": {
"match": {
"name": "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}}]
}
}
POST /book/_search
{
"query": {
"match": {
"name": "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}},{"description":{}}]
}
}
POST /book/_search
{
"query": {
"query_string" : {
"query" : "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}},{"description":{}}]
}
}在使用match查询的同时,加上一个highlight属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- name:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
结果:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.6153753,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.6153753,
"_source" : {
"name" : "ElasticSearch",
"description" : "Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布
式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为
Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够
达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、
Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch
是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。",
"price" : 999.99,
"timestamp" : "2020-08-15 10:11:35"
},
"highlight" : {
"name" : [
"<font color='pink'>ElasticSearch</font>"
],
"description" : [
"<font color='pink'>Elasticsearch</font>是一个基于Lucene的搜索服务器。它
提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。",
"<font color='pink'>Elasticsearch</font>是用Java语言开发的,并作为
Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。",
"<font color='pink'>Elasticsearch</font>用于云计算中,能够达到实时搜索,
稳定,可靠,快速,安装使用方便。",
"根据DB-Engines的排名显示,<font color='pink'>Elasticsearch</font>是最
受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。"
]
}
}
]
}
}文档批量操作(bulk 和 mget)
mget 批量查询
单条查询 GET /test_index/_doc/1,如果查询多个id的文档一条一条查询,网络开销太大。
GET /_mget
{
"docs" : [
{
"_index" : "book",
"_id" : 1
},
{
"_index" : "book",
"_id" : 2
}
]
}返回:
{
"docs" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "lucene",
"description" : "Lucene Core is a Java library providing powerful
indexing and search features, as well as spellchecking, hit highlighting and
advanced analysis/tokenization capabilities. The PyLucene sub project provides
Python bindings for Lucene Core. ",
"price" : 100.45,
"timestamp" : "2020-08-21 19:11:35"
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "solr",
"description" : "Solr is highly scalable, providing fully fault tolerant
distributed indexing, search and analytics. It exposes Lucenes features through
easy to use JSON/HTTP interfaces or native clients for Java and other
languages.",
"price" : 320.45,
"timestamp" : "2020-07-21 17:11:35"
}
}
]
}同一索引下批量查询:
GET /book/_mget
{
"docs" : [
{
"_id" : 2
},
{
"_id" : 3
}
]
}搜索简化写法
POST /book/_search
{
"query": {
"ids" : {
"values" : ["1", "4"]
}
}
}bulk 批量增删改
Bulk 操作解释将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数。
语法:
POST /_bulk
{"action": {"metadata"}}
{"data"}如下操作,删除1,新增5,修改2。
POST /_bulk
{ "delete": { "_index": "book", "_id": "1" }}
{ "create": { "_index": "book", "_id": "5" }}
{ "name": "test14","price":100.99 }
{ "update": { "_index": "book", "_id": "2"} }
{ "doc" : {"name" : "test"} }功能:
- delete:删除一个文档,只要1个json串就可以了 删除的批量操作不需要请求体
- create:相当于强制创建 PUT /index/type/id/_create
- index:普通的put操作,可以是创建文档,也可以是全量替换文档
- update:执行的是局部更新partial update操作
格式:每个json不能换行。相邻json必须换行。
隔离:每个操作互不影响。操作失败的行会返回其失败信息。
实际用法:bulk请求一次不要太大,否则一下积压到内存中,性能会下降。所以,一次请求几千个操 作、大小在几M正好。
bulk会将要处理的数据载入内存中,所以数据量是有限的,最佳的数据两不是一个确定的数据,它取决 于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(ES的 config下的elasticsearch.yml)中配置。
http.max_content_length: 10mb