
什么是大数据,本质?
数据的存储:分布式文件系统(分布式存储)---->HDFS:Hadoop Distributed File System----->起源于GFS:Google File System
数据的计算:分布式计算
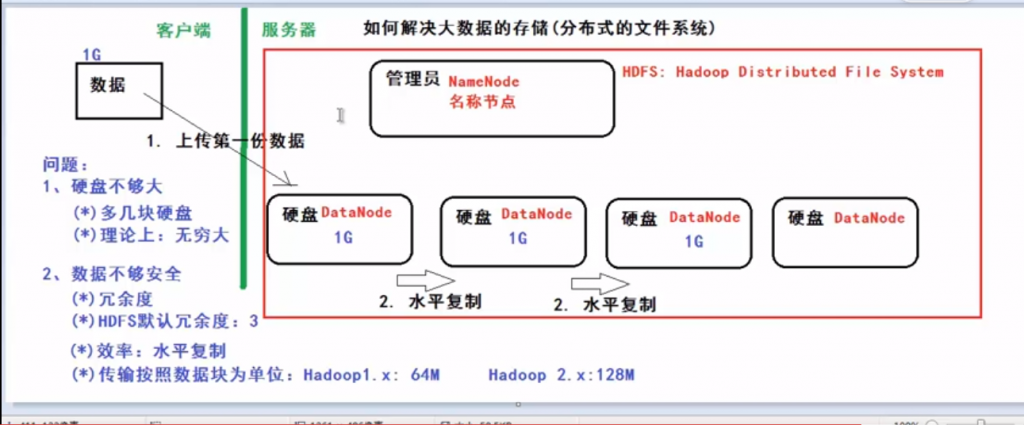
如何解决大数据的存储?
分布式文件系统(HDFS,来源于GFS)
举例:网盘(GFS:没有硬盘的,数据只能存储于内存中。)
| 问题 | 解决方案 |
| 硬盘不够大 | 多几块硬盘 理论上:无穷大 |
| 数据不够安全 | 冗余度 默认冗余度是:3 效率:水平复制 传输按照数据块为单位:Hadoop1.x:64M Hadoop2.x:128M |
Hadoop的安装模式
- 本地模式:1台
- 伪分布模式:1台
- 全分布模式:3台
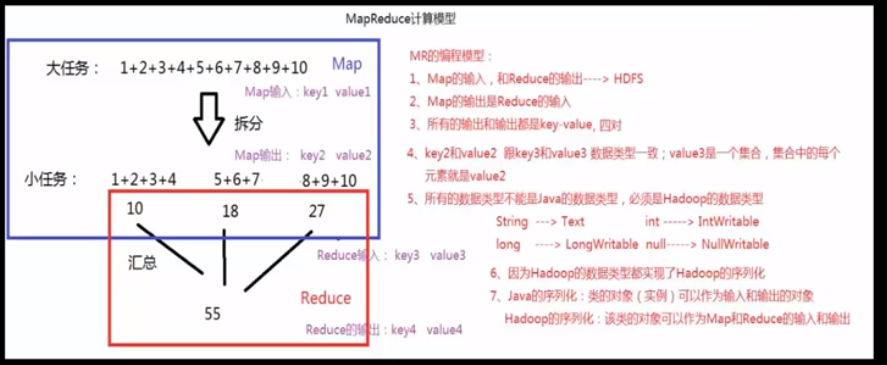
如何解决大数据的计算?
分布式计算
什么是PageRank(MapReduce的问题来源)
搜索排名
MapReduce(java语言实现)
基础编程模型:把一个大任务拆分成小任务,再进行汇总
Hadoop的背景起源
Hadoop的背景起源
BigTable---->大表------------->NoSQL数据库:Hbase
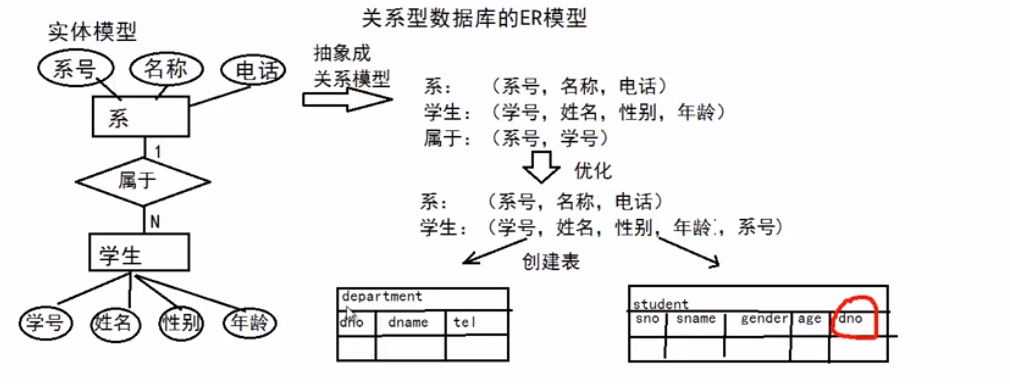
关系数据库(ORacle,Mysql,SQL Server)的特点
---什么是关系型数据库?基于关系模型(基于二维表)所提出的一种数据库
---ER(Entity-Relationalship)模型:通过增加外键来减少数据的冗余
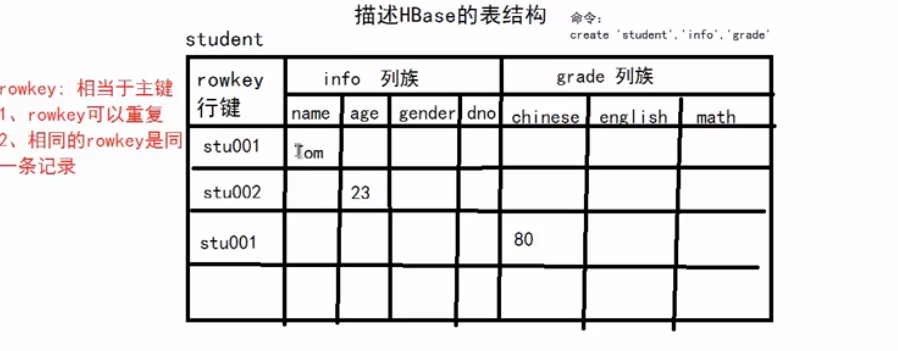
什么是BigTable
把所有的数据保存到一张表中,采用冗余--->好处:提高效率
- 因为优了BigTable的思想:NoSQL:Hbase
- HBase基于Hadoop的HDFS的
- 描述HBase的表结构

{kind=link}
一条评论 “Hadoop的背景起源:GFS、MapReduce、BigTable”